
01. 배열과 문자열
배열이나 문자열에 대한 문제들은 서로 대체 가능하다.
해시 테이블
해시테이블을 효율적인 탐색을 위한 자료구조로서 키(key)를 값에 대응시킨다. 간단한 해시 테이블을 구현하기 위해선 연결리스트와 해시 코드 함수만 있으면 된다. 키와 값을 해시테이블에 넣을때는 다음의 과정을 거친다.
- 처음에 키의 해시 코드를 계산한다.(키의 자료형은 보통 int, long이 된다. 키의 개수는 무한대지만 int의 개수는 유한하므로 서로 다른 두 개의 키가 같은 해시 코드를 가리킬 수 있다.)
- hash(key) % array.length와 같은 방식으로 해시 코드를 이용해서 배열의 인덱스를 구한다.(서로 다른 해시코드가 같은 인덱스를 가리킬 수 있다.)
- 배열의 각 인덱스에는 키와 값으로 이루어진 연결 리스트가 존재한다. 키와 값을 해당 인덱스에 저장한다. (충돌에 대비해서 반드시 연결리스트를 이용해야 한다.)
키에 상응하는 값을 찾기 위해서는 다음과 같은 과정을 반복해야 한다.
- 주어진 키로부터 해시 코드를 계산한다.
- 해시 코드를 이용해서 인덱스를 계산한다.
- 해당 키에 상응하는 값을 연결리스트에서 탐색한다.
충돌이 자주 발생한다면 최악의 경우 수행 시간은 O(N)이 된다. (N은 키의 갯수) 충돌을 최소화하도록 잘 구현된 경우 탐색시간은 O(1)이다.
또 다른 구현법으로는 균형 이진 탐색 트리를 사용하는 방법이 있다. 이 경우 탐색 시간이 O(logN)이 된다. 이 방법은 크기가 큰 배열을 미리 할당해 놓지 않아도 되기 때문에 잠재적으로 적은 공간을 사용한다는 장점이 있다.
ArrayList와 가변 크기 배열
특정 언어에서 배열의 크기를 자동으로 조절할 수 있다. 자바 같은 언어에서 배열은 길이가 고정되어 있다. 동적 가변 크기 기능이 내재되어 있는 배열과 비슷한 자료구조를 원할 때는 보통 ArrayList를 사용한다. ArrayList는 필요에 따라 크기를 변화시킬 수 있으면서도 O(1)의 접근 시간을 유지한다. 통상적으로 배열이 가득 차는 순간, 배열의 크기를 두 배로 늘린다. 크기를 늘리는 순간은 O(N)이지만, 자주 발생하는 일이 아니라서 상환입력시간으로 계산했을 때 여전히 O(1)이 된다.
StringBuilder
문자열 리스트가 주어졌을 때 이 문자열을 하나로 이어붙이려는 경우 이때 수행시간은 어떻게 될까?
1
2
3
4
5
6
7
String joinWord(String[] words) {
String sentence = "";
for(String w : words) {
sentence = sentence + w;
}
return sentence;
}
문자열을 이어붙일 때마다 두 개의 문자열을 읽어 들인 뒤 문자를 하나하나 새로운 문자열에 복사해야 한다. 따라서 총 수행시간은 O(x+2x+…nx) -> O(xn²)이 된다.
StringBuilder를 사용하면 이 문제를 해결할 수 있다. 이는 단순하게 가변 크기 배열을 이용해서 필요한 경우에만 문자열을 복사하게끔 해준다.
1
2
3
4
5
6
7
String joinWord(String[] words) {
StringBuilder sentence = new StringBuilder();
for(String w : words) {
sentence.append(w);
}
return sentence.toString();
}
면접 문제
- 중복이 없는가 : 문자열이 주어졌을 때, 중복되어 등장하는 문자열이 있는지 확인하는 알고리즘을 작성하라
- 순열 확인 : 문자열 두 개가 주어졌을 때, 이 둘이 서로 순열 관계에 있는지 확인하는 메서드를 작성하라 (순열이란? 문자열을 재배치하는 것을 뜻한다.)
- URI화 : 문자열에 들어있는 모든 공백을 ‘%20’으로 바꿔주는 메서드를 작성하라, 모든 문자를 다 담을 수 있을 만큼 충분한 공간이 이미 확보되어 있으면 문자열의 최종 길이가 함께 주어진다고 가정해도 된다.
- 회문 순열 : 주어진 문자열이 회문의 순열인지 아닌지 확인하는 함수를 작성하라 (회문이란? 앞으로 읽으나 뒤로 읽으나 같은 단어 혹은 구절을 의미한다.)
- 하나 빼기 : 문자열을 같게 만들기 위한 편집 횟수가 1회 이내인지 확인하는 함수를 작성하라 (문자열 편집에는 문자삽입, 문자삭제, 문자교체)가 있다.
- 문자열 압축 : 반복되는 문자의 개수를 세는 방식의 기본적인 문자열 압축 메서드를 작성하라 예)aabccccaaaa -> a2b1c4a4 만약 압축된 문자열의 길이가 기존 문자열의 길이보다 길다면 기존 문자열을 반환해야 한다.
- 행렬 회전 : 이미지를 표현하는 N X N 행렬이 있다. 이미지의 각 픽셀은 4 바이트로 표현된다. 이때, 이미지를 90도 회전시키는 메서드를 작성하라. 행렬을 추가로 사용하지 않고서도 할 수 있겠는가
- O 행렬 : M X N 행렬의 한 원소가 0일 경우, 해당 원소가 속한 행과 열의 모든 원소를 0으로 설정하는 알고리즘을 작성하라.
- 문자열 회전 : 한 단어가 다른 문자열에 포함되어 있는지 판별하는 isSubstring이라는 메서드가 있다고 할 때, s1과 s2의 두 문자열이 주어졌고, s2가 s1을 회전시킨 결과인지 판별하고자 한다. isSubstring을 한 번만 호출해서 판별할 수 있는 코드를 작성하라
02. 연결리스트
연결리스트는 차례로 연결된 노드를 표현해주는 자료구조이다. 단방향 연결리스트에서 각 노드는 다음 노드를 가리킨다. 양방향 연결리스트에서 각 노드는 다음 노드와 이전 노드를 함께 가리킨다.
배열과 달리 연결리스트에서는 특정 인덱스를 상수 시간에 접근할 수 없다. 즉 리스트에서 k번째 원소를 찾고 싶다면 처음부터 k번 루프를 돌아야 한다. 리스트의 장점은 리스트의 시작 지점에서 아이템을 추가하거나 삭제하는 연산을 상수 시간에 할 수 있다는 점이다.
연결리스트 만들기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//단방향 연결리스트
class Node {
Node next = null;
int data;
public Node(int d) {
data = d;
}
void appendToTail(int d) {
Node end = new Node(d);
Node n = this;
while(n.next != null) {
n = n.next;
}
n.next = end;
}
}
연결리스트에 접근할 때 head 노드의 주소를 참조하는 방법을 사용했다. 이런식으로 구현할 때는 약간 조심해야 하는 부분이 있는데 여러 객체들이 동시에 연결리스트에 참조하는 도중에 head가 바뀌면 어떻게 해야 할지 생각해 봐야 하는 것이다. head가 바뀌었음에도 어떤 객체들은 이전 head를 계속 가리키고 있을 수도 있다.
할 수 있다면, Node 클래스를 포함하는 LinkedList 클래스를 만드는 게 좋다. 그렇게 하면 해당 클래스 안에 head Node 변수를 단 하나만 정의해 놓음으로써 위의 문제점을 완전히 해결할 수 있기 때문이다.
면접에서 연결리스트에 대해 이야기 할 때는 단방향 연결리스트에 대한 이야기인지 양방향 연결리스트에 대한 이야기인지 반드시 인지하고 있어야 한다.
단방향 연결리스트에서 노드 삭제
연결리스트에서 노드를 삭제하는 연산은 꽤 직관적이다. 노드 n이 주어지면, 그 이전 노드 prev를 찾아 prev.next를 n.next와 같도록 설정한다. 리스트가 양방향 연결리스트인 경우에는 n.next가 가리키는 노드를 갱신하여 n.next.prev가 n.prev와 같도록 설정해야 한다. 여기서 유의할 점은 1)널 포인터 검사를 반드시 해야한다. 2)필요하면 head와 tail 포인터도 갱신해야 한다.
Runner 기법
Runner는 부가 포인터라고도 하며, 연결리스트 문제에서 많이 활용되는 기법이다. 연결리스트를 순회할 때 두 개의 포인터를 동시에 사용하는 것이다. 이때 한 포인터가 다른 포인터보다 앞서도록 한다.
재귀 문제
연결리스트 관련 문제 가운데 상당수는 재귀 호출에 의존한다. 연결리스트 문제를 푸는 데 어려움을 겪고 있다면, 재귀적 접근법은 통할지 확인해 봐야 한다.
면접 문제
- 중복 없애기 : 정렬되어 있지 않은 연결리스트가 주어졌을 때 이 리스트에서 중복되는 원소를 제거하는 코드를 작성하라
- 뒤에서 k번째 원소 구하기 : 단방향 연결리스트가 주어졌을 때 뒤에서 k번째 원소를 찾는 알고리즘을 구하라
- 중간 노드 삭제 : 단방향 연결리스트가 주어졌을 때 중간에 있는 노드 하나를 삭제하는 알고리즘을 구현하라(단, 삭제할 노드에만 접근할 수 있다.)
- 분할 값 : x가 주어졌을 때 x보다 작은 노드들을 x보다 크거나 같은 노드들보다 앞에 오도록 하는 코드를 작성하라
- 리스트의 합 : 표현된 숫자 두 개가 있을 때, 이 두수를 더하여 그 합을 연결리스트로 반환하는 함수를 작성하라. 예)(7->1->6) + (5->9->2) = 617 + 295
- 회문 : 주어진 연결리스트가 회문인지 검사하는 함수를 작성하라
- 교집합 : 단방향 연결리스트 두 개가 주어졌을 때 이 두 리스트의 교집합 노드를 찾은 뒤 반환하는 코드를 작성하라 (교집합은 노드의 값이 아닌 주소가 완전히 같은 경우를 말한다.)
- 루프 발견 : 순환 연결리스트가 주어졌을 때, 순환되는 부분의 첫째 노드를 반환하는 알고리즘을 작성하라
03. 스택과 큐
스택 구현하기
스택 자료구조는 말그대로 데이터를 쌓아 올린다는 의미이다. 문제의 종류에 따라 배열보다 스택에 데이터를 저장하는 것이 더 적합한 방법일 수 있다.
스택은 Last-In-First-Out 에 따라 자료를 배열한다.
- pop() : 스택에서 가장 위에 있는 항목을 제거한다.
- push(item) : item 하나를 스택의 가장 윗 부분에 추가한다.
- peek() : 스택의 가장 위에 있는 항목을 반환한다.
- isEmpty() : 스택이 비어있을 때 true를 반환한다.
배열과 달리 스택은 상수 시간에 i번째 항목에 접근할 수 없다. 하지만 스택에서 데이터를 추가하거나 삭제하는 연산은 상수 시간에 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public class MyStack {
private static class StackNode{
private T data;
private StackNode next;
public StackNode(T data) {
this.data = data;
}
}
private StackNode top;
public T pop() {
if (top = null) throw new EmptyStackException() ;
T item = top. data;
top = top.next;
return item;
}
라 StackNode t = new StackNode (item);
t.next = top;
top = t.
}
public T peek(){
if (top == null) throw new EmptyStackException ();
return top.data;
}
public boolean isEmpty () {
return top == null;
}
}
스택이 유용한 경우는 재귀 알고리즘을 사용할 때다. 재귀적으로 함수를 호출해야 하는 경우에 임시 데이터를 스택에 넣어 주고, 재귀 함수를 빠져나와 퇴각 검색을 할 때는 스택에 넣어 두었던 임시 데이터를 빼 줘야 한다.
큐 구현하기
큐는 First-In-First-Out 순서에 따른다. 큐에 저장되는 항목들은 큐에 추가되는 순서대로 제거된다.
- add(item) : item을 리스트 끝 부분에 추가한다.
- remove() : 리스트의 첫 번째 항목을 제거한다.
- peek() : 큐에서 가장 위에 있는 항목을 반환한다.
- isEmpty() : 큐가 비어 있을 때는 true를 반환한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public class MyQueue {
private static class QueueNode {
private T data;
private QueueNode next;
public QueueNode (T data) {
this. data = data;
}
}
private QueueNode first;
private QueueNode last;
public void add (T item) {
QueueNode t = new QueueNode(item);
if (last != null) {
last.next = t;
}
last = t;
if (first == null) {
first = last;
}
}
public T remove() {
if (first == null) throw new NoSuchElementException ();
T data = first. data;
first = first. next;
if (first == null) {
last = null;
}
return data;
}
public T peek() {
if (first == null) throw new NoSuchElementException () ;
return first.data;
}
public boolean isEmpty () {
return first == null;
}
큐에서 처음과 마지막 노드를 갱신할 때 실수가 나오기 쉽다. 큐는 너비 우선 탐색을 하거나 캐시를 구현하는 경우에 종종 사용된다.
면접 문제
- 한 개로 세 개 : 배열 한 개로 스택 세 개를 어떻게 구현할지 설명하라
- 스택 Min : 기본적인 push와 pop 기능이 구현된 스택에서 최소값을 반환하는 min 함수를 추가하려고 한다. 어떻게 설계할 수 있겠는가?
- 접시 무더기 : 접시 무더기를 생각해보면 접시를 너무 높이 쌓으면 무너져 내릴 것이다. 현실에서는 무더기가 어느 정도 높아지면 새로운 무더리를 만든다. 이것을 흉내내는 자료구조 SetOfStack을 구현해보라
- 스택으로 큐 : 스택 두 개로 큐 하나를 구현한 MyQueue 클래스를 구현하라
- 스택 정렬 : 가장 작은 값이 위로 오도록 스택을 정렬하는 프로그램을 작성하라
- 동물 보호소 : 먼저 들어온 동물이 먼저 나가는 동물 보호소가 있을때 사람들은 보호소에서 가장 오래된 동물부터 입양할 수 있는데 개와 고양이중 어떤 동물을 데려갈지 선택할 수 있다. 이 시스템을 자료구조로 구현하
04. 트리와 그래프
트리에서 탐색하는 것이 배열이나 연결리스트처럼 선형으로 구성된 자료구조에서 탐색하는 것보다 훨씬 까다롭다. 또 최악의 수행시간과 평균적 수행시간이 매우 크게 바뀔 수 있어서, 알고리즘을 살펴볼 때에는 두 가지 측면 모두를 반드시 따져 봐야 한다.
트리의 종류
트리를 이해하기 위한 좋은 방법 중 하나는 재귀적 설명법을 사용하는 것이다.
- 트리는 하나의 루트 노드를 갖는다.
- 루트 노드는 0개 이상의 자시 노드를 갖고 있다.
- 그 자식노드 또한 0개 이상의 자식 노드를 갖고 있다.
트리에는 사이클이 존재할 수 없다. 노드들은 특정 순서로 나열될 수도 있고, 그럴 수 없을 수도 있다. 각 노드는 어떤 자료형으로도 표현 가능하다.
트리 및 그래프 문제들은 대부분 세부사항이 모호하거나 가정 자체가 틀린 경우가 많다. 아래의 이슈들을 유의하고 명확하게 해줄 것을 요구하자.
- 트리 vs 이진 트리 : 이진 트리는 각 노드가 최대 두 개의 자식을 갖는 트리를 말한다.
- 이진 트리 vs 이진 탐색 트리 : 이진 탐색 트리는 모든 노드가 특정 순서를 따르는 속성이 있는 이진 트리를 일컫는다. 많은 지원자들이 트리 문제가 주어지면 이진 탐색트리 일 것이라고 가정해 버린다. 이진탐색 트리인지 아닌지 확실하게 묻도록 하자
- 균형 vs 비균형 : 많은 트리가 균형 잡혀 있긴 하지만, 전부 그런것은 아니다. 면접관에게 어느쪽인지 묻도록 하자.
- 완전 이진 트리 : 완전 이진 트리는 트리의 모든 높이에서 노드가 꽉 차 있는 이진 트리를 말한다. 마지막 단계는 꽉차있지 않아도 되지만 노드가 왼쪽에서 오른쪽으로 채워져야 한다.
- 전 이진 트리 : 전 이진 트리는 모든 노드의 자식이 없거나 정확히 두 개 있는 경우를 말한다. (자식이 하나만 있는 노드가 존재해서는 안 된다.)
- 포화 이진 트리 : 포화 이진 트리는 전 이진 트리이면서 완전 이진 트리인 경우를 말한다. 모든 말단 노드는 같은 높이에 있어야 하며, 마지막 단계에서 노드의 개수가 최대가 되어야 한다.
이진 트리 순회
- 중위 순회 : 중위 순회는 왼쪽 가지, 현재 노드, 오른쪽 가지 순서로 노드를 방문하고 출력하는 방법을 말한다. 이진 탐색 트리를 이 방식으로 순회한다면 오름차순으로 방문하게 된다.
- 전위 순회 : 전위 순회는 자식 노드보다 현재 노드를 먼저 방문하는 방법을 말한다. 전위 순회에서 가장 먼저 방문하게 될 노드는 언제나 루트이다.
- 후위 순회 : 후위 순회는 모든 자식 노드들을 먼저 방문한 뒤 마지막에 현재 노드를 방문하는 방법을 말한다. 후위 순회에서 가장 마지막에 방문하게 될 노드는 언제나 루트이다.
이진 힙(최소힙과 최대힙)
최소힙은 트리의 마지막 단계에서 오른쪽 부분을 뺀 나머지 부분이 가득 채워져 있다는 점에서 완전 이진 트리이며, 각 노드의 원소가 자식들의 원소보다 작다는 특성이 있다. 따라서 루트는 트리 전체에서 가장 작은 원소가 된다. 최대 힙은 원소가 내림차순으로 정렬되어 있다는 점만 다를 뿐 최소힙과 완전히 같다.
- 삽입 : 최소힙에 원소를 삽입할 때는 언제나 트리의 밑바닥에서부터 삽입을 시작한다. 완전 트리의 속성에 위배되지 않게 새로운 원소는 밑바닥 가장 오른쪽 위치로 삽입된다. 힙에 있는 노드의 개수를 n이라 할 때, 연산은 O(log n)시간이 걸린다.
- 최소 원소 뽑아내기 : 최소힙에서 최소 원소를 찾기란 가장 쉬운 일이다. 최소 원소는 언제나 가장 위에 놓인다. 최솟값을 어떻게 힙에서 제거하느냐가 까다로운 부분이다.
트라이(접두사 트리)
트라이는 n-차 트리의 변종으로 각 노드에 문자를 저장하는 자료구조이다. 따라서 트리를 아래쪽으로 순회하면 단어 하나가 나온다.
널 노드라고도 불리우는 * 노드는 종종 단어의 끝을 나타낸다. * 노드의 실제 구현은 특별한 종류의 자식 노드로 표현될 수도 있다.
트라이에서 각 노드는 1개에서 ALPHABET_SIZE + 1개까지 자식을 갖고 있을 수 있다. 트라이는 길이가 K인 문자열이 주어졌을 때 O(K) 시간에 해당 문자열이 유효한 접두사인지 확인할 수 있다.
그래프
트리는 그래프의 한 종류이다. 그렇다고 모든 그래프가 트리는 아니다. 트리는 사이클이 없는 하나의 연결 그래프이다.
그래프는 단순히 노드와 그 노드를 연결하는 간선을 하나로 모아 놓은 것과 같다.
그래프에는 방향성이 있을 수도 있고, 없을 수도 있다. 방향성이 있는 간선은 일방통행, 방향성이 없는 간선은 양방향 통행 도로라고 생각하면 된다. 모든 정점 쌍간에 경로가 존재하는 그래프는 연결 그래프라고 부른다. 그래프에는 사이클이 존재할 수도 있고, 존재하지 않을 수도 있다. 사이클이 없는 그래프는 비순환 그래프라고 부른다.
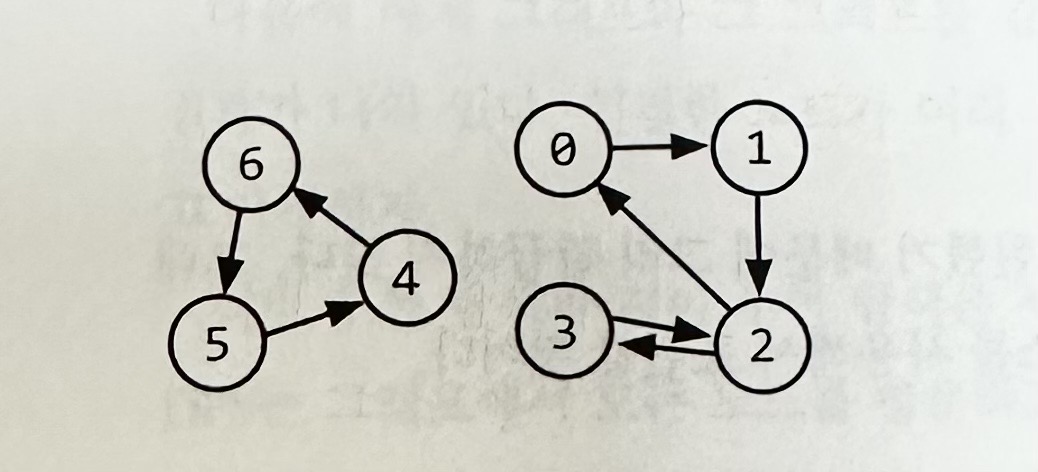
인접 리스트 : 인접 리스트는 그래프를 표현할 때 사용되는 가장 일반적인 방법이다. 모든 정점을 인접 리스트에 저장한다. 그래프는 트리와 달리 특정 노드에서 다른 모든 노드로 접근이 가능하지는 않다.
1
2
3
4
5
6
7
8
9
//그래프 클래스는 트리의 노드 클래스와 같아 보인다.
class Graph {
public Node[] nodes;
}
class Node {
public String name;
public Node[] children;
}
인접 행렬 : 인접 행렬은 N x N 불린 행렬로써 matrix[i][j]가 true라면 i에서 j로의 간선이 있다는 뜻이다. (???) 무방향 그래프를 인접 행렬로 표현한다면 이 행렬은 대칭행렬이 된다.
그래프 탐색 : 그래프를 탐색하는 방법으로는 깊이 우선 탐색과 너비 우선 탐색이 있다.
- 깊이 우선 탐색은 루트 노드에서 시작해서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법을 말한다. (넓게 탐색하기 전에 깊에 탐색한다.)
- 너비 우선 탐색은 루트 노드에서 시작해서 인접한 노드를 먼저 탐색하는 방법을 말한다.
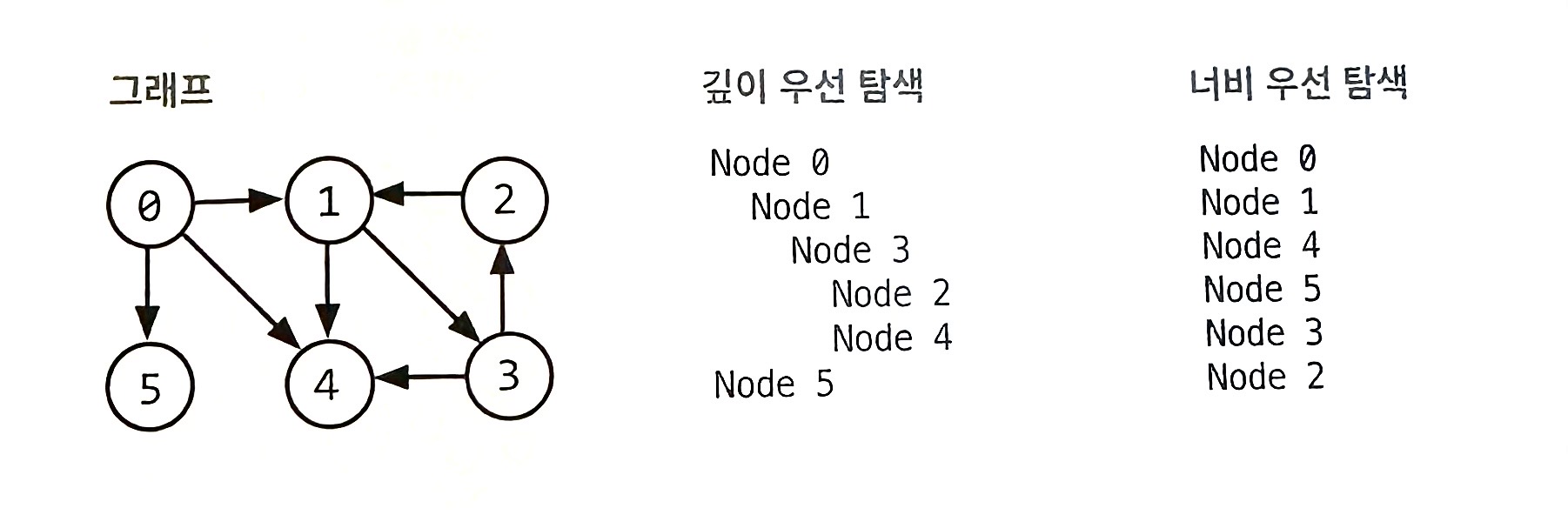
깊이 우선 탐색(DFS)는 그래프에서 모든 노드를 방문하고자 할 때 더 선호되는 편이다. a노드를 방문한 뒤 a와 인접한 노드들을 차례로 순회한다. a와 인접한 b를 방문했다면, a와 인접한 또 다른 노드를 방문하기 전에 b의 이웃 노드들을 전부 방문해야 한다.
그래프 탐색시 어떤 노드를 방문했었는지 여부를 반드시 검사해야 한다. 이를 검사하지 않는다면 무한루프에 빠질 수 있다.
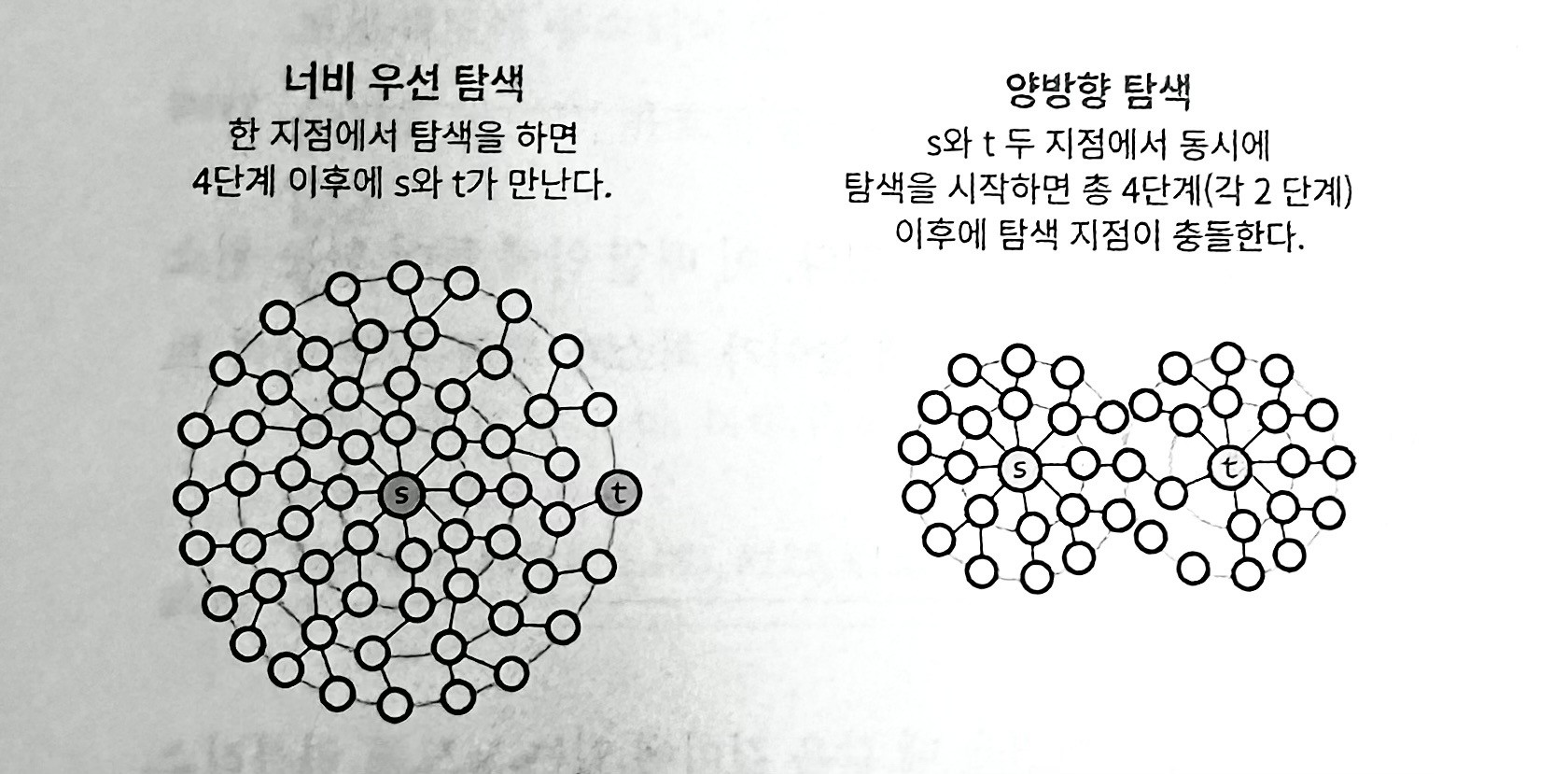
두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때는 너비 우선 탐색(BFS)가 일반적으로 더 낫다.
너비 우선 탐색은 직관적이지 않은 면이 있다. 가장 많은 실수가 BFS가 재귀적으로 동작할 것이라 가정하는데 재귀적으로 동작하지 않는다. BFS는 큐를 사용한다. a 노드에서 시작한다고 했을 때 BFS는 a 노드의 이웃 노드를 모두 방문한 다음에 이웃의 이웃들을 방문한다. 즉 a에서 시작해서 거리에 따라 단계별로 탐색한다고 볼 수 있다.
양방향 탐색 : 양방향 탐색은 출발지와 도착지 사이에 최단 경로를 찾을 때 사용되곤 한다. 기본적으로 출발지와 도착지 두 노드에서 동시에 너비 우선 탐색을 수행한 뒤 두 탐색 지점이 충돌하는 경우에 경로를 찾는 방식이다.
면접 문제
- 노드 사이의 경로 : 방향 그래프가 주어졌을 때 두 노드 사이에 경로가 존재하는지 확인하는 알고리즘을 작성하라
- 최소 트리 : 오름차순으로 정렬된 배열이 있다. 이 배열안에 들어있는 원소는 정수이며 중복된 값이 없다고 했을 때 높이가 최소가 되는 이진탐색트리를 만드는 알고리즘을 작성하라
- 깊이의 리스트 : 이진 트리가 주어졌을 때 같은 깊이에 있는 노드를 연결리스트로 연결해주는 알고리즘을 설계하라
- 균형 확인 : 이진 트리가 균형 잡혀있는지 확인하는 함수를 작성하라
- BST 검증 : 주어진 이진 트리가 이진 탐색 트리인지 확인하는 함수를 작성하라
- 후속자 : 이진 탐색 트리에서 주어진 노드의 다음 노드를 찾는 알고리즘을 작서앟라
- 순서 정하기 : 프로젝트의 리스트와 프로젝트들 간의 종속 관계가 주어졌을 때 프로젝트를 수행해 나가는 순서를 찾으라
- 첫 번째 공통 조상 : 이진 트리에서 노드 두 개가 주어졌을 때 이 두 노드의 첫번째 공통 조상을 찾는 알고리즘을 설계하고 그 코드를 작성하라
- BST 수열 : 배열의 원소를 왼쪽에서부터 차례로 트리에 삽입함으로써 이진 탐색 트리를 생성할 수 있다. 이진 탐색 트리 안에서 원소가 중복되지 않는 다고 할 때, 해당 트리를 만들어 낼 수 있는 모든 가능한 배열을 출력하라.
- 하위 트리 확인 : 두 개의 커다란 이진 트리 T1과 T2가 있다고 하자. T1이 T2 보다 훨씬 크다고 했을 때, T2가 T1의 하위 트리(subtree)인지 판별하는 알 고리즘올 만들라.
- 임의의 노드 : 이진 트리 클래스를 바닥부터 구현하려고 한다. 노드의 삽입, 검색, 삭제뿐만 아니라 임의의 노드를 반환하는 getRandomNode() 메서드도 구현한다. 모든 노드를 같은 확률로 선택해주는 getRandomNode 메서드를 설계하고 구현하라
- 합의 경로 : 각 노드의 값이 정수인 이진 트리가 있다. 이때 정수의 합이 특정 값이 되도록 하는 경로의 개수를 세려고 한다. 경로는 꼭 위에서 아래로 내려가야 한다. 즉 부모 노드에서 자식 노드로만 움직일 수 있다. 이 알고리즘을 설계하라
05. 비트 조작
비트 조작 기법은 다양한 문제에서 활용된다. 명시적으로 요구하는 문제들도 있는 한편, 코드를 최적화할 때 유용하게 사용되는 기법으로 활용되기도 한다. 비트 조작 코드를 작성하는 능력뿐 아니라 손으로도 그릴 수 있도록 익숙해 지는 것이 좋다.
손으로 비트 조작 해보기

비트 조작을 할 때 알아야 할 사실들과 트릭들
비트 조작 문제를 풀 때 다음의 표현식들을 알아 두면 좋다.
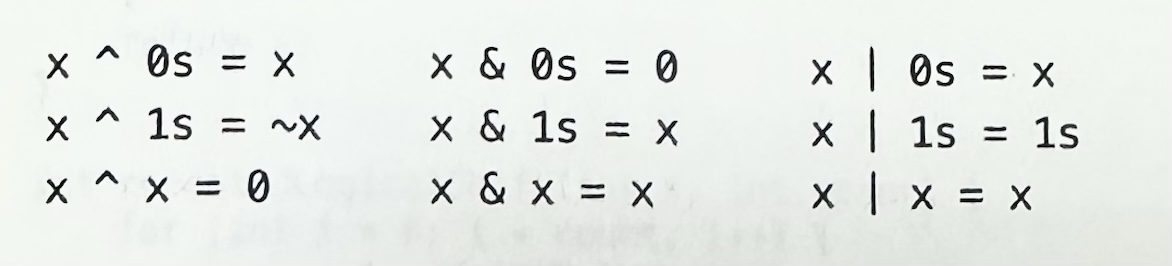
위 표현식들을 이해하기 위해서는 연산들이 비트 단위로 이루어진다는 사실을 명심해야 한다. 한 비트에서 일어나는 일이 다른 비트에 어떤 영향도 미치지 않는다. 그러므로 위 표현식이 한 비트에 대해 참이라면 일련의 비트들에 대해서도 참이 된다.
산술 우측 시프트 vs 논리 우측 시프트
산술 우측 시프트는 기본적으로 2로 나눈 결과와 같다. 논리 우측 시프트는 우리가 일반적으로 비트를 옮길 때 보이는 것처럼 움직인다.
논리 우측 시프트는 비트를 옆으로 옮긴 다음에 최상위 비트에 0을 넣는다. 즉, »> 연산과 같다.
기본적인 비트 조작 : 비트값 확인 및 채워넣기
비트값 확인
1
2
3
4
5
6
//이 메서드는 1을 i비트만큼 시프트해서 00010000과 같은 값을 만든다.
//그 다음 AND 연산을 통해 num의 i번째 비트를 뺀 나머지 비트를 모두 삭제한 뒤, 이 값을 0과 비교한다.
//만약 이 값이 0이 아니라면 i번째 비트는 1이어야 하고, 0이라면 i번째 비트는 0이어야 한다.
boolean getBit(int num, int i) {
return((num & (1 << i)) != 0);
}
비트값 채워넣기
1
2
3
4
5
6
//SetBit는 1 i비트만큼 시프트해서 00010000과 같은 값을 만든다.
//그 다음 OR 연산을 통해 num의 i번째 비트값을 바꾼다.
//i번째를 제외한 나머지 비트들은 0과 OR 연산을 하게 되므로 num에 아무 영향을 끼치지 않는다.
int setBit(int num, int i) {
return num | (1 << i);
}
비트값 삭제하기
1
2
3
4
5
6
//이 메서드는 setBit를 거의 반대로 한 것과 같다. NOT 연산자를 이용해 00010000 -> 11101111과 같이 만든 뒤 num과 AND 연산을 수행한다.
//그러면 나머지 비트의 값은 변하지 않은채 i번째 비트값만 삭제된다.
int clearBit(int num, int i) {
int mask = ~(1 << i);
return num & mask;
}
비트값 바꾸기
i번째 비트값을 v로 바꾸고 싶다면 우선 11101111과 같은 값을 이용해 (i=4인 경우) i번째 비트값을 삭제해야 한다. 그 뒤 우리가 바꾸고자 하는 값 v를 왼쪽으로 i번 시프트한다.
면접 문제
- 삽입 : 두 개의 32비트 수 N과 M이 주어지고, 비트 위치 i와 j가 주어졌을 때, M을 N에 삽입하는 메서드를 구현하라.
- 2진수를 문자열로 : 0.72와 같이 0 과 1 사이의 실수가 double 타입으로 주어 졌을 때, 그 값을 2진수 형태로 출력하는 코드를 작성하라.
- 비트 뒤집기 : 어떤 정수가 주어졌을 때 여러분은 이 정수의 비트 하나를 0에서 1로 바꿀 수 있다. 이때 1이 연속으로 나올 수 있는 가장 긴 길이를 구하는 코드를 작성하라.
- 다음 숫자 : 양의 정수가 하나 주어졌다. 이 숫자를 2진수로 표기했을 때 1 비트의 개수가 같은 숫자중에서 가장 작은 수와 가장 큰 수를 구하라.
- 디버거 : 다음 코드가 하는 일을 설명하라
((n & (n-1)) == 0) - 변환 : 정수 A와 B를 2진수로 표현했을 때 A를 B로 바꾸기 위해 뒤집어야 하는 비트의 개수를 구하는 함수를 작성하라
- 쌍끼리 맞바꾸기 : 명령어를 가능한 한 적게 사용해서 주어진 정수의 짝수 번째 비트의 값과 홀수번째 비트의 값을 바꾸는 프로그램을 작성하라
- 선 그리기 : 흑백 모니터 화면은 하나의 바이트 배열에 저장되는데, 인접한 픽셀 여덟 개를 한 바이트에 묶어서 저장한다. 화면의 폭은 w이며, w는 8로 나누어 떨어진다. 이때 (x1, y)에서 (x2, y)까지 수평선을 그려주는 함수를 작성하라
06. 수학 및 논리 퍼즐
많은 문제들이 수학 혹은 컴퓨터 과학에 기초해서 만들어졌기 때문에 대부분 논리적인 추론으로 해법을 찾을 수 있다.
소수
모든 자연수는 소수의 곱으로 나타낼 수 있다는 규칙이 있다.
- 가분성 : 어떤 수 x로 y를 나눌 수 있으려면 x를 소수의 곱으로 분할하였을 때 나열되는 모든 소수는 y를 소수의 곱으로 분할하였을 때 나열되는 모든 소수들의 부분집합이어야 한다.
- 소수판별 : 어떤 수 n이 소수인지 여부를 판별하는 가장 단순한 방법은 2에서 n-1까지 루프를 돌면서 나누어지는 경우가 있는지 확인해 보는 것이다.
- 소수 목록 만들기(에라토스테네스의 체) : 에라토스테네스의 체는 소수 목록을 만드는 굉장히 효율적인 방법이다. 이 알고리즘은 소수가 아닌 수들은 반드시 다른 소수로 나누어진다는 사실에 기반해서 동작한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
boolean [] sieve0fEratosthenes(int max) {
boolean[] flags = new boolean [max + 1];
int count = 0;
init(flags); // 0과 1번 인덱스를 제외한 모든 원소값을 true로 초기화한다.
int prime = 2;
while (prime s= Math.sart (max)) {
/* prime의 배수들을 지워나간다. */
cross0ff(flags, prime);
/* 그다음 true로 세팅된 인덱스를 찾는다. */
prime = getNextPrime (flags, prime);
}
return flags;
}
void crossOff (boolean [] flags, int prime) {
/* prime의 배수들을 제거해나간다. K < prime인 k에 대한 k * prime은
* 이전 루프에서 이미 제거되었을 것이므로 prime * prime부터 시작한다. */
for (int i = prime * prime; i < flags.length; i += prime)
flags [i] = false;
}
}
int getNextPrime (boolean [] flags, int prime) {
int next = prime + 1;
while (next < flags.length && !flags[next]) {
next++;
}
return next;
}
확률
확률은 까다롭게 느껴질 수 있지만 기본적으로는 논리적인 추론이 가능한 몇 가지 법칙에 기반한다.
<img src=”/assets/img/posting_img/book/코딩인터뷰/확률.jpeg” width=”700px””>
A ∩ B의 확률
위 벤다이어그램에 다트를 던진다고 생각했을 때 A와 B의 두 원이 겹치는 부분에 다트가 떨어질 확률은 얼마나 되는가? A에 떨어질 확률과 A와 B가 겹치는 부분의 비율도 알고 있다면, 그 확률은 다음과 같이 표현할 수 있다. P(A∩B) = P(B|A)P(A)
예) 1~10까지의 수 중 하나를 뽑는다고 할 때, 5보다 작거나 같으면서 동시에 짝수인 수를 뽑을 확률은 얼마가 되는가? 1-5까지의 수를 뽑을 확률은 50%이고, 1~5 중에서 짝수를 뽑을 확률은 40%다. 따라서 두 경우에 모두 속할 확률은 다음과 같다. P(x=짝수∩x<= 5) = P(x=짝수∩x<=5)P(x<=5)=(2/5)*(1/2)=1/5
A ∪ B의 확률
다트가 A 또는 B에 떨어질 확률은 각 영역에 떨어질 확률은 알고 있고, 겹치는 부분에 떨어질 확률도 알고 있다면, A 혹은 B에 떨어질 확률은 다음과 같이 표현할 수 있다. P(A∪B)=P(A)+P(B)-P(A∩B)
여기서 독립사건과 상호 배타적인 사건의 확률을 구하는 특수 규칙들을 쉽게 얻을 수 있다.
독립성 : A와 B가 독립사건(발생한 사건 사이에 아무런 관계가 없는 경우)이라면, A가 B에 아무런 영향을 끼치지 않으므로 P(B A)=P(B)가 되고 따라서 P(A∩B)=p(A)가 된다. - 상호 배타성 : A와 B가 상호 배타적이라면 P(A∩B)=0이 되므로 P(A∪B)를 계산할 때 P(A∩B)항은 제거해도 된다. 따라서 P(A∪B)=P(A)+P(B)가 된다.
두 사건의 확률이 전부 0보다 큰 경우에 이 두 사건이 독립적이면서 상호 배타적인 것은 불가능하다. 두 사건중 하나의 확률이 0이라면 두 사건은 독립적이면서 상호 배타적이다.
입을 열라
수수께끼 같은 문제를 만나게 되면 당황하지 말라, 면접관들이 원하는 것은 여러분이 문제를 어떻게 공략해 나가는지 보는 것이다. 입을 열어 말을 하고, 문제를 어떻게 공략해 나가는지 면접관들에게 보여주라.
규칙과 패턴을 찾으라
많은 경우에 문제를 풀다가 발견하는 규칙이나 패턴을 따로 적어두면 도움이 된다. (사실 반드시 적어두는 것이 낫다.)
예) 끈이 두 개가 있다. 각 끈은 태우는데 정확히 한 시간이 걸린다. 이 두 끈을 사용해 15분을 재려면 어떻게 해야되겠는가? 끈의 밀도는 균일하지 않아서 절반의 길이를 태우는데 드는 시간이 정확히 30분이라는 보장은 없다.
[규칙]
- 태우는 데 x분이 걸리는 끈과 y분이 걸리는 끈이 주어지면, x+y만큼의 시간을 잴 수 있다.
- 태우는 데 x분이 걸리는 끈이 주어지면, x/2분을 잴 수 있다.
- 1번 끈을 태우는 데 x분 걸리고 2번 끈을 태우는 데 y분이 걸리면, 2번 끈을 태우는 시간을 (y-x)분이나 (y-x/2)분으로 바꿀 수 있다.
이 규칙들을 조합하면 전부 태우는 데 한 시간 걸리는 2번 끈을 30분 걸리는 끈으로 바꿀 수 있다. 그다음 2번 끈의 양쪽에 불을 붙여 버리면 2번 끈은 15분 뒤에 전부 타버린다. 그러니 다음의 순서대로 해보자
- 1번 끈은 양쪽에 불을 붙이고, 2번 끈은 한쪽에만 불을 붙인다.
- 1번 끈이 다 타들어가면 30분이 지난 것이다. 따라서 2번 끈이 다 타기 위해 남은 시간은 30분이다.
- 그 시점에 2번 끈의 다른 쪽에도 불을 붙인다.
- 그러면 정확히 15분 뒤에 2번 끈도 완전히 다 타버릴 것이다.
최악의 경우는?
수수께끼 종류의 문제 중 많은 수가 최악의 경우를 최소화하는 것와 연관이 있다. 어떤 행동을 최소화하는 문제일 수도 있고, 지정된 횟수 안에 처리해야 하는 문제일 수도 있다. 그럴 때는 최악의 상황을 균형 맞추도록 하면 도움이 된다.
알고리즘적 접근법
문제를 풀다가 막혔다면, 알고리즘 문제를 푸는 접근법 가운데 하나를 적용해 보자. 수수께끼처럼 보이는 문제들 중 상당수는 기술적인 측면을 제거한 알고리즘 문제인 경우가 많다.
면접 문제
- 무거운 알약 : 약병 20개가 있다. 이중 19개에는 1.0그램짜리 알약들이 들어있고, 하나에는 1.2그램짜리 알약들이 들어 있다. 저울이 주어졌을때 무거운 약병을 찾으려면 어떻게 해야 할까? 저울은 딱 한 번만 쓸 수 있다.
- 도미노 : 8X8 크기의 체스판이 있는데 대각선 반대 방향 끝에 있는 셀 두 개가 떨어져 나갔다. 하나의 도미노로 정확히 두 개의 정사각형을 덮을 수 있을 때, 31개 도미노로 보드 전체를 덮을 수 있겠는가?
- 삼각형 위의 개미 : 개미 세 마리가 삼각형의 각 꼭짓점에 있다. 개미 세 마리가 삼각형 모서리를 따라 걷기 시작했을 때, 두 마리 혹은 세 마리 전부가 충돌할 확률은 얼마인가?
- 물병 : 5리터짜리 물병과 3리터 짜리 물병이 있다. 물은 무제한으로 주어지지만 계량컵은 주어지지 않는다. 이 물병 두 개를 사용해서 정확히 4리터 물을 계량하려면 어떻게 해야 할까?
- 계란 떨어뜨리기 문제 : 100층짜리 건물이 있다. N층 혹은 그 위 어딘가에서 계란이 떨어지면 그 계란은 부서진다. 하지만 N층 아래 어딘가에서 떨어지 면 깨지지않는다. 계란 두 개가 주어졌을 때, 최소 횟수로 계란을 떨어뜨려서 N을 찾으라.
- 100 라커 : 복도에 100개의 라커가 있다. 어떤 남자가 100개의 라커 문을 전부 연다. 그러고 나서 짝수 번호의 라커를 전부 닫는다. 그 다음에는 번호가 3의 배수인 라커를 순서대로 찾아다니며 열려 있으면 닫고, 닫혀 있으면 연다. 이런 식으로 복도를 100번 지나가면(마지막에는 100번째 라커의 문을 열거나 닫을 것이다) 열린 라커문은 몇 개가 되겠는가?
- 독극물 : 1,000개의 음료수 중 하나에 독극물이 들어 있다. 그리고 독극물을 확인해 볼 수 있는 식별기 10개가 주어졌다. 독극물 한 방울을 식별기에 떨어뜨리면 식별기가 변한다. 만약 식별기에 독극물을 떨어뜨리지 않았다면 몇 번이든 재사용해도 된다. 하지만 이 테스트는 하루에 한 번만 할 수 있으며 결과를 얻기까지 일주일이 걸린다. 독극물이 든 음료수를 가능한 한 빨 리 찾아내려면 어떻게 해야 할까?
07. 객체 지향 설계
객체 지향 설계에 관한 문제들은 기술적 문제 또는 실제 생활에서 접할 수 있는 객체들을 구현하는 클래스와 메서드를 대략적으로 그려보는 문제다. 이런 문제들을 통해 지원자들이 어떤 코딩 스타일을 갖고 있는지 알아볼 수 있다.
접근법
객체가 나타내는 것이 물리적 개체이건 기술적 작업이건 간에 객체 지향 설계에 관한 질문들은 거의 비슷한 방식으로 공략 가능하다.
- 모호성의 해소 : 객체 지향 설계 관련 문제들은 대개 고의적으로 모호성을 띄고 있다. 면접관들은 여러분이 스스로 가정을 만들어내고, 질문을 통해 명확히 해나가는 과정을 살펴보고 싶어하기 때문이다. 객체 지향 설계에 관한 질문을 받으면, 누가 그것을 사용할 것이며 어떻게 사용할 것인지에 대한 질문을 던져야 한다.
- 핵심 객체의 설계 : 시스템에 넣을 핵심 객체가 무엇인지 생각해 봐야 한다.
- 관계 분석 : 핵심 객체를 결정했다면, 객체 사이의 관계를 분석해야 한다. 어떤 객체가 어떤 객체에 속해 있는가? 다른 객체로부터 상속받아야 하는 객체는 있나? 관계는 다대다 관계인가 아니면 일대다 관계인가?
- 행동 분석 : 이제 남은 일은 객체가 수행해야 하는 핵심 행동들에 대해서 생각하고, 이들이 어떻게 상호작용해야 하는지 따져 보는 것이다.
디자인 패턴
면접관은 지식이 아닌 능력을 평가할 것이므로 디자인 패턴은 보통 면접 범위 외로 친다. 하지만 싱글톤, 팩터리 메서드와 같은 디자인 패턴을 알아두면 면접 볼 때 특히 유용하다.
여러분의 소프트웨어 엔지니어링 기술을 향상시키는 가장 좋은 방법은 디자인 패턴에 관한 책을 하나 골라 공부하는 것이다.
- 싱글톤 클래스 : 싱글톤 패턴은 어떤 클래스가 오직 하나의 객체만을 갖도록 하며, 프로그램 전반에 걸쳐 그 객체 하나만 사용되도록 보장해야 한다.
- 팩터리 메서드 : 팩터리 메서드는 어떤 클래스의 객체를 생성하기 위한 인터페이스를 제공하되, 하위 클래스에서 어떤 클래스를 생성할지 결정할 수 있도록 도와준다. 한 가지 방법은 Factory 메서드 자체에 대한 구현은 제공하지 않고 객체 생성 클래스를 abstract로 선언하고 놔두는 것이다.
면접 문제
- 카드 한 벌 : 카드 게임에 쓰이는 카드 한 벌을 나타내는 자료구조를 설계하라.
- 콜 센터 : 고객 응대 담당자, 관리자, 감독관 이렇게 세 부류의 직원들로 구성된 콜 센터가 있다고 할 때, 콜 센터로 오는 전화는 먼저 상담이 가능한 고객 응대 담당자로 연결돼야 한다. 고객 응대 담당자가 처리할 수없는 전화는 관리자로 연결되고, 관리자가 처리할 수 없는 전화는 다시 감독관에게 연결된다. 이 문제를 풀기 위한 자료구조를 설계하라
- 주크박스 : 객체 지향 원칙에 따라 음악용 주크박스를 설계하라
- 주차장 : 객체 지향 원칙에 따라 주차장을 설계하라
- 온라인 북 리더 : 온라인 북 리더 시스템에 대한 자료구조를 설계하라
- 직소 : N x N 크기의 직소 퍼즐을 구현하라. 자료구조를 설계하고, 퍼즐을 푸는 알고리즘을 설명하라
- 채팅 서버 : 채팅 서버를 어떻게 구현할 것인지 설명하라
- 지뢰찾기 : 텍스트 기반의 지뢰찾기 게임을 설계하고 구현하라.
- 파일 시스템 : 메모리 상주형 파일 시스템을 구현하기 위한 자료구조와 알고리즘에 대해 설명해 보라
- 해시 테이블 : 체인(연결리스트)를 사용해 충돌을 해결하는 해시테이블을 설계하고 구현하라
08. 재귀와 동적 프로그래밍
재귀와 관련된 문제들은 아주 많지만 상당수는 패턴이 비슷하다. 주어진 문제가 재귀 문제인지 확인해 보는 좋은 방법은, 해당 문제를 작은 크기의 문제로 만들 수 있는지 보는 것이다.
다음과 같은 문장으로 시작하는 문제는 재귀로 풀기 적당한 문제일 가능성이 높다. “n번째…를 계산하는 알고리즘을 설계하라”, “첫 n개를 나열하는 코드를 작성하라”, “모든 …를 계산하는 메서드를 구현하라” 등등
접근법
재귀적 해법은 부분문제에 대한 해법을 통해 완성된다. 믾은 경우 단순히 f(n-1)에 대한 해답에 무언가를 더하거나, 제거하거나, 아니면 그 해답을 변경하여 f(n)을 계산해낸다. 주어진 문제를 부분문제로 나누는 방법도 여러 가지가 있다. 가장 흔하게 사용되는 세 가지 방법으로는 다음이 있다.
- 상향식 접근법 : 상향식 접근법은 가장 직관적인 경우가 많다. 우선 간단한 경우들에 대한 풀이법을 발견하는 것으로부터 시작한다.
- 하향식 접근법 : 하향식 접근법은 덜 명확해서 복잡해 보일 수 있다. 이러한 문제들은 어떻게 하면 N에 대한 문제를 부분 문제로 나눌 수 있을지 생각해 봐야 한다.
- 반반 : 데이터를 절반으로 나누는 방법도 종종 유용하다. 예) 이진 탐색
재귀적 해법 vs 순환적 해법
재귀적 알고리즘은 사용하면 공간 효율성이 나빠질 수 있다. 재귀 호출이 한 번 발생할 때마다 스택에 새로운 층을 추가해야 한다. (재귀의 깊이가 n일 때 O(n)만큼의 메모리를 사용하게 된다는 것을 의미한다.) 이런 이유로 재귀적 알고리즘을 순환적으로 구현하는 것이 더 나을 수 있다.
동적 계획법 & 메모이제이션
동적 프로그래밍은 거의 대부분 재귀적 알고리즘과 반복적으로 호출괴는 부분문제를 찾아내는 것이 관건이다. 이를 찾은 뒤 나중을 위해 현재 결과를 캐시에 저장해 놓으면 된다.
동적 프로그래밍을 설명하는 가장 간단한 예시는 n번째 피보나치 수를 찾는 것이다. 이런 문제를 풀 때는 일반적인 재귀로 구현한 뒤 캐시 부분을 나중에 추가하는 것이 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
//피보나치 수열
//1) 재귀
int fibonacci(int i) {
if(i==0) return 0;
if(i==1) return 1;
return fibonacci(i-1) + fibonacci(i-2);
}
//2) 하향식 동적 프로그래밍(메모이제이션)
int fibonacci(int n) {
return fibonacci(n, new int[n + 1]);
}
int fibonacci(int i, int[] memo) {
if (i = 0 || i == 1) return i;
if (memo[i] == 0) {
memo[i] = fibonacci(i - 1, memo) + fibonacci(i - 2, memo);
}
return memo[i];
}
//3) 상향식 동적 프로그래밍
int fibonacci(int n) {
if (n == 0) return 0;
else if (n == 1) return 1;
int[] memo = new int[n];
memo[0] = 0:
memo[1] = 1;
for (int i = 2; i < n; i++) {
memo[i] = memo [i - 1] + memo [i - 2];
}
return memo[n - 1] + memo [n - 2];
}
면접 문제
- 트리플 스텝 : 어떤 아이가 n개의 계단을 오른다. 한 번에 1계단 오르기도 하고, 2계단이나 3계단을 오르기도 한다. 계단을 오르는 방법이 몇 가지가 있는지 계산하는 메서드를 구현하라
- 격자판 상의 로봇 : 행의 개수는 r, 열의 개수는 c인 격자판의 왼쪽 상단 꼭짓점에 로봇이 놓여 있다고 할 때, 이 로봇은 오른쪽 아니면 아래쪽으로만 이동할 수 있다.
- 마술 인덱스 :
배열 A[0 ... n-1]에서 A[i] = i인 인덱스를 마술 인덱스라 정의한다. 정렬된 상태의 배열이 주어졌을 때, 마술 인덱스가 존재한다면 그 값을 찾는 메서드를 작성하라. - 부분 집합 : 어떤 집합의 부분집합을 전부 반환하는 메서드를 작성하라
- 재귀 곱셈 : * 연산자를 사용하지 않고 양의 정수 두 개를 곱하는 재귀 함수를 작성하라
- 괄호 : n쌍의 괄호로 만들 수 있는 모든 합당한 조합을 출력하는 알고리즘을 구현하라
- 영역 칠하기 : 이미지 편집 프로그램에서 흔히 쓰이는 영역 칠하기 함수를 구현하라
09. 시스템 설계 및 규모 확장성
규모 확장성은 가장 쉬운 종류의 문제이다. 이런류의 문제들은 단순히 여러분이 실제 세계에서 어떻게 행동할지를 보기 위해 설계된 문제들이다.
문제를 다루는 방법
- 소통하라 : 시스템 설계 문제를 출제하는 가장 큰 목적은 의사소통 능력을 평가하기 위함이다. 면접관과 끊임없이 의사소통하라, 질문을 던지고 시스템에 발생할 수 있는 문제점을 열린 마음으로 받아들여라
- 처음에는 포괄적으로 접근하라 : 알고리즘으로 바로 뛰어들지 말고, 특정 부분을 과도하게 파고들지 말라
- 화이트보드를 사용하라
- 면접관이 우려하는 부분을 인정하라
- 가정을 할 때 주의하라
- 여러분이 생각하는 가정을 명확히 언급하라 : 가정을 할 때는 그것을 면접관에게 알려 줘야 한다.
- 필요하다면 어림잡아 보라
- 뛰어들라 : 지원자로서 문제를 책임져야 한다. 그렇다고 조용히 있으면 안 된다. 반드시 면접관과 이야기를 해야 한다.
시스템 설계 : 단계별 접근법
- 문제의 범위를 한정하라 : 설계해야 할 시스템에 대해 잘 모르고 있다면 시스템을 설계할 수 없다. 만들고자 하는 시스템과 면접관이 원하는 것이 같은지 확실히 할 수 있다는 점에서 문제의 범위를 한정하는 작업은 중요하다.
- 합리적인 가정을 만들라 : 필요하다면 가정을 세우는 것도 괜찮지만 합당해야한다.
- 중요한 부분을 먼저 그리라 : 시스템의 주요한 부분을 다이어그램으로 그려라. 시스템의 처음부터 마지막까지 어떻게 동작하는지 그 흐름을 보이라.
- 핵심 문제점을 찾으라 : 기본적인 설계를 마친 뒤에는 발생할 수 있는 핵심 문제에 집중해야 한다. 어느 부분이 병목지점일까? 이 시스템이 풀어야할 주된 문제는 무엇인가?
- 핵심 문제점을 해결할 수 있도록 다시 설계하라 : 핵심 문제가 무엇인지 알아냈다면 그에 맞게 설계를 수정해야 한다. 또 알고있는 제약사항들을 면접관과 이야기하는 것 또한 중요하다.
규모 확장을 위한 알고리즘: 단계별 접근법
단순히 시스템의 한부분 혹은 알고리즘을 설계해 보라는 요청을 받을 수도 있는데 이때도 반드시 규모 확장성을 신경써야 한다.
- 질문하라 : 초반에는 문제를 제대로 이해했는지 확인하기 위한 질문 시간이 필요하다. 문제가 무엇인지 확실하게 이해하지 못한 상태에서는 문제 자체를 풀 수가 없다.
- 현실적 제약을 무시하라 : 메모리 제약이 없고, 컴퓨터 한 대에서 모든 데이터를 다 처리할 수 있다고 가정해보라
- 현실로 돌아오라 : 원래 문제로 돌아와서 컴퓨터 한 대에 저장할 수 있는 데이터의 크기는 얼마나 되고, 데이터를 여러 조각으로 쪼갰을 때 어떤 문제가 발생할지 생각해 보라
- 문제를 풀어라 : 발견된 문제점들을 어떻게 해결할지 생각해 봐야 한다.
시스템 설계의 핵심 개념
특정 개념을 알고 있으면 문제를 더 쉽게 풀 수 있다.
수평적 vs 수직적 규모 확장
- 수직적 규모 확장 : 특정 노드의 자원의 양을 늘리는 방법을 말한다. 예) 서버의 메모리를 추가해서 서버의 처리 능력을 향상시킬 수 있다.
- 수평적 규모 확장 : 노드의 개수를 늘리는 방법을 말한다. 예) 서버를 추가함으로써 서버 한 대가 다뤄야 하는 부하를 줄일 수 있다.
서버 부하 분산 장치
일반적으로 규모 확장성이 있는 웹사이트의 프론트엔드 부분은 서버 부하 분산 장치를 통해서 제공된다. 이렇게 해야 서버에 걸리는 부하를 여러 대의 서버에 균일하게 분산시킬 수 있고, 서버 한 대 때문에 전체 시스템이 죽거나 다운되는 상황을 방지할 수 있다.
데이터베이스 역정규화와 NoSQL
SQL 같은 관계형 데이터베이스의 조인 연산은 시스템이 커질수록 굉장히 느려진다. 따라서 조인 연산은 가능하면 피해야 한다. 역정규화를 사용하면 데이터베이스의 정보를 추가해서 읽기 연산의 속도를 향상시킬 수 있다. 또는 NoSQL 데이터베이스를 사용할 수도 있다. NoSQL은 조인 연산 자체를 지원하지 않는다. 따라서 자료를 저장할 때 조금 다른 방식으로 구성해 놓는데, 이 방식이 규모 확장성에 좋도록 설계되어 있다.
데이터 베이스 분할(샤딩)
샤딩은 데이터를 여러 컴퓨터에 나눠서 저장하는 동시에 어떤 데이터가 어떤 컴퓨터에 저장되어 있는지 알 수 있는 방식을 말한다.
- 수직적 분할 : 자료의 특성별로 분할하는 방식, 단점으로는 특정 테이블의 크기가 일정 수준이상으로 커지면, 데이터베이스를 재분할해야 할 수도 있다.
- 키 혹은 해시 기반 분할 : 간단하게 구현하자면 mod(key, n)의 값을 이용해서 N개의 서버에 분할 저장하면 된다. 문제는 서버를 새로 추가할 때마다 모든 데이터를 다시 재분배해야 하는데, 굉장히 비용이 큰 작업이다.
- 디렉터리 기반 분할 : 데이터를 찾을 때 사용되는 조회 테이블을 유지하는 방법이다. 이 방법은 상대적으로 서버를 추가하기 쉽지만 심각한 단점으로는 조회 테이블이 단일 장애지점이 될 수 있고, 지속적으로 테이블을 읽는 행위가 전체 성능에 영향을 미칠 수 있다.
캐싱
인메모리 캐시를 사용하면 결과를 굉장히 빠르게 가져올 수 있다. 인메모리 캐시는 키-값을 쌍으로 갖는 간단한 구조로써 일반적으로 애플리케이션과 데이터 저장소 사이에 자리잡고 있다.
비동기식 처리 & 큐
이상적인 경우 속도가 느린 연산은 비동기식으로 처리해야 한다. 그렇지 않으면 해당 연산이 끝나기까지 하염없이 기다려야 할 수도 있기 때문이다. 어떤경우에는 연산을 미리 해 놓을 수 있다.
네트워크 성능 척도
네트워크의 성능을 측정할 때 사용되는 몇 가지 중요한 척도는 다음과 같다.
- 대역폭 : 단위 시간에 전송할 수 있는 데이터의 최대치를 말한다. 보통 초당 몇 비트를 보낼 수 있는지로 계산한다.
- 처리량 : 처리량은 단위 시간에 실제로 전송된 데이터의 양을 의미한다.
- 지연 속도 : 데이터를 전송하는 데 걸리는 시간을 말한다.
예) 공장의 컨베이어 벨트에서 물품이 이동할때, 지연 속도는 물품 하나가 한 지점에서 다른 지점까지 옮겨지는 데 걸린 시간을 말하고, 처리량은 단위 시간에 옮겨진 물품의 개수를 의미한다.
- 컨베이어 벨트의 폭을 넓힌다고 지연속도가 달라지지는 않는다. 하지만 처리량과 대역폭을 바꾼다면 달라질 수 있다.
- 벨트의 길이를 줄이면 각 물품이 벨트 위에서 보내는 시간이 줄어들기 때문에 지연 속도 또한 줄어들 것이다.
- 컨베이어 벨트의 속도를 빠르게 만든다면 위의 세 가지 척도를 모두 바꿀 수 있다.
- 대역폭은 최상의 조건에서 단위 시간에 전송할 수 있는 물품의 개수를 뜻한다. 처리량은 실제 상황에서 단위 시간에 전송된 물품의 개수를 말한다.
지연 시간은 무시되기 쉽지만 특정 상황에선 굉장히 중요한 역할을 한다.
MapReduce
MapReduce 프로그램은 보통 굉장히 커다란 데이터를 처리하는 데 사용된다. MapReduce 프로그램을 사용하려면 Map 단계와 Reduce 단계를 구현해야 한다. 나머지 부분은 시스템이 알아서 처리할 것이다.
- Map 은 데이터를 입력으로 받은 뒤 key, value 쌍을 반환한다.
- Reduce는 키와 값들을 입력으로 받은 뒤 처리과정을 거쳐 새로운 키와 값을 반환한다. 경우에 따라 이 결과를 또 다른 Reduce 프로그램에 넘길 수도 있다.
MapReduce는 많은 과정을 병렬로 처리할 수 있게 도와주기 때문에 굉장히 커다란 데이터에 대해서도 규모 확장이 쉬워진다.
시스템 설계시 고려할 점
- 실패 : 시스템의 어떤 부분이든 실패 가능성이 존재한다. 따라서 각 부분이 실패했을 때를 대비한 대비책을 준비해야 한다.
- 가용성 및 신뢰성 : 가용성은 사용 가능한 시스템의 시간을 백분율로 나타낸 것을 말한다. 신뢰성은 특정 단위 시간에 시스템이 사용 가능할 확률을 나타낸 것을 말한다.
- 읽기 중심 vs 쓰기 중심 : 쓰는 연산이 많다면 큐를 사용하는 방법을 생각해보고, 읽는 연산이 많다면 캐시를 사용하는 것이 좋을 수 있다.
- 보안 : 해당 시스템이 직면할 수 있는 문제점에 대해 생각해 보고 그를 해결하기 위해 어떻게 시스템을 설계할지 생각해보라
완벽한 시스템은 없다
어떤 시스템에 대해서도 완벽하게 동작하는 시스템 설계란 존재하지 않는다. 이런 종류의 문제를 받았을 때 여러분이 해야 할 일은 사례를 잘 이해하고, 문제의 범위를 설정하고, 합리적인 가정을 세운뒤, 명확하게 설계한 시스템을 만드는 것이다.
연습 문제
수백 만 개의 문서가 주어졌을 때, 특정 단어 리스트가 포함된 문서를 찾으려고 한다. 어떻게 할 수 있을까? 단어가 등장하는 순서는 중요하지 않지만, 해당 단어가 완벽하게 나타나야 한다.
- 처음에는 문서가 겨우 수십 개 있을 때를 가정하고 문제를 풀어 본다. 한 가지 방법은 전처리 과정을 통해 모든 문서에 대한 해시테이블을 만드는 것이다.
- 문서의 개수가 수백만 개로 늘어나면 어떻게 해야 할까? 일단 문서를 여러 대의 컴퓨터로 나눠서 보내야 할 것이다. 데이터를 나누려면 다음과 같은 사항들을 고민해야 한다.
- 해시테이블은 어떻게 분할할 것인가? 키워드에 따라 나눌 수 있다. 어떤 단어에 대한 문서 목록은 컴퓨터 한 대에 온전히 저장될 것이다. 즉 전체 문서 집합 가운데 특정한 부분집합에 대한 해시 테이블만 한 컴퓨터에 두는 것이다.
- 데이터를 분할하기로 결정하면, 어떤 컴퓨터에서는 문서를 처리하고 그 처리 결과를 다른 컴퓨터로 옮겨야 할 수 있다.
- 어떤 컴퓨터에 어떤 데이터가 보관되어 있는지 알 수 있어야 한다.
- 각 문제점들에 대한 해법을 찾아야 한다. 한 가지 방법은 키워드를 알파벳 순서에 따라 분할하는 것이다. 즉 한 컴퓨터가 특정한 범위의 단어들만 통제하게 하는 것이다.
면접 문제
- 주식 데이터
- 소셜 네트워크 : 페이스북, 링크드인과 같은 대규모 소셜 네트워크를 위한 자료구조는 어떻게 설계하겠는가?
- 웹 크롤러 : 웹에 있는 데이터를 긁어오는 크롤러를 설계할 때 무한루프에 빠지는 일을 방지하려면 어떻게 해야 하는가?
- 중복 URL : 100억 개의 URL이 있다. 중복된 문서를 찾으려면 어떻게 해야 하는가?
- 캐시 : 최근 검색 요청을 캐시에 저장하는 메커니즘을 설계하라, 또 데이터가 바뀌었을 때 어떻게 캐시를 갱신할 것인지 반드시 설명하라
- 판매 순위 : 전자상거래 회사에서 가장 잘 팔리는 각 목록별 리스트를 알고 싶어할 때, 이 시스템을 어떻게 설계할지 설명하라
- 개인 재정 관리자
- Pastebin : 텍스트를 입력하면 접속 가능한 임의의 URL을 생상한 뒤 반환해주는 시스템을 설계하라
10. 정렬과 탐색
많은 정렬 및 탐색 문제는 잘 알려진 알고리즘들을 변용하여 출제된다. 그러므로 여러 가지 정렬 알고리즘의 차이점을 잘 이해하고, 해당 상황에서 어떤 알고리즘이 어울릴지 살펴두는 것이 좋다.
예) Person 객체로 이루어진 아주 크기가 큰 배열이 있을 때, 이 배열에 담긴 객체들을 나이순으로 정렬하라.
- 배열의 크기가 크므로 효율성이 매우 중요하다.
- 나이순으로 정렬하는 것이므로, 그 값의 범위가 좁다는 것을 알 수 있다.
위 예에서 버킷 정렬 또는 기수 정렬이 가장 적합하다. 버킷의 크기를 1년으로 설정하면 O(n)에 정렬할 수 있다.
널리 사용되는 정렬 알고리즘
- 버블 정렬 : 평균 및 최악 실행시간 O(n²), 메모리 O(1) 버블 정렬은 배열의 첫 원소부터 순차적으로 진행하며, 현재 원소가 그 다음 원소의 값보다 크면 두 원소를 바꾸는 작업을 반복한다.
- 선택 정렬 : 평균 및 최악 실행시간 O(n²), 메모리 O(1) 선택 정렬은 심플한 알고리즘이다.(하지만 비효율적) 배열을 선형 탐색하며 가장 작은 원소를 배열 맨 앞으로 보낸다. 그 다음 두 번째로 작은 원소를 찾은 뒤 앞으로 보내 준다.
- 병합 정렬 : 평균 및 최악 실행 시간 O(nlogn), 메모리-상황에 따라 다름, 병합 정렬은 배열을 절반씩 나누어 각각을 정렬한 다음 이 둘을 합하여 다시 정렬하는 방법이다. 이 알고리즘에서는 병합 처리하는 것이 가장 복잡하다. 병합 작업을 수행하는 메서드는 병합 대상이 되는 배열의 두 부분을 임시 배열에 복사하고, 왼쪽 절반의 시작 지점과 오른쪽 절반의 시작 지점을 추적한다. 그 다음 임시 배열을 순회하면서 두 배열에서 더 작은 값의 원소를 꺼내어 원래 배열에 복사해 넣는다. 두 배열중 한 배열에 대한 순회가 끝난 경우 다른 배열의 남은 부분을 원래 배열에 남김없이 복사해 넣고 작업을 마친다.
- 퀵 정렬 : 평균 O(nlogn), 최악O(n²), 메모리 O(logn) 퀵 정렬은 무작위로 선정된 한 원소를 사용하여 배열을 분할하는데, 선정된 원소보다 작은 원소들은 앞에, 큰 원소들은 뒤로 보낸다. 배열 분할 작업은 연속된 스왑 연산을 통해 효율적으로 수행된다. 하지만 배열 분할에 사용되는 원소가 중간값에 가까운 값이 되리라는 보장이 없기 때문에, 정렬 알고리즘이 느리게 동작할 수도 있다.
- 기수 정렬 : 실행시간 O(kn) 기수 정렬 알고리즘은 데이터가 정수처럼 유한한 비트로 구성되어 있는 경우에 사용된다. 기수 정렬은 각 자릿수를 순회해 나가면서 각 자리의 값에 따라 그룹을 나눈다.
- 탐색 알고리즘 : 탐색 알고리즘에서 일반적인 것은 이진 탐색이다. 이진 탐색은 정렬된 배열의 원소 x를 찾고자 할 때 사용된다. x를 중간에 위치한 원소와 비교한 뒤 x가 중간에 위치한 값보다 작다면 배열의 왼쪽 절반을 재탐색 하고, 크다면 배열의 오른쪽 절반을 재탐색한다. 이 과정을 x를 찾거나 부분배열의 크기가 0이 될 때까지 반복한다.
면접 문제
- 정렬된 병합 : 정렬된 배열 A와 B가 주어진다. A의 끝에는 B를 전부 넣을 수 있을 만큼 충분한 여유 공간이 있다. B와 A를 정렬된 상태로 병합하는 메서드를 작성하라
- Anagram 묶기 : 철자 순서만 바꾼 문자열이 서로 인접하도록 문자열 배열을 정렬하는 메서드를 작성하라
- 회전된 배열에서 검색 : n개의 정수로 구성된 정렬 상태의 배열을 임의의 횟수만큼 회전시켜 얻은 배열이 입력으로 주어졌을 때, 이 배열에서 특정한 원소를 찾는 코드를 작성하라
- 크기를 모르는 정렬된 원소 탐색
- 드문드문 탐색 : 빈 문자열이 섞여 있는 정렬된 문자열 배열이 주어졌을 때, 특정 문자열의 위치를 찾는 메서드를 작성하라
- 큰 파일 정렬 : 한 줄에 문자열 하나가 쓰여있는 20GB짜리 파일이 있다고 할 때, 이 파일을 정렬하려면 어떻게 해야할지 설명하라
- 빠트린 정수 : 음이 아닌 정수 40억개로 이루어진 입력 파일이 있다. 이 파일에 없는 정수를 생성하는 알고리즘을 작성하라(단 메모리는 1GB만 사용할 수 있다.)
- 중복 찾기 : 1부터 N까지의 숫자로 이루어진 배열이 있다. 배열엔 중복된 숫자가 나타날 수 있고, N이 무엇인지는 알 수 없다. 사용 가능한 메모리가 4KB일 때, 중복된 원소를 모두 출력하려면 어떻게 할 수 있을까?
- 정렬된 행렬 탐색 : 각 행과 열이 오름차순으로 정렬된 M X N 행렬이 주어졌을 때 특정한 원소를 찾는 메서드를 구현하라
- 스트림에서의 순위 : 정수 스트림을 읽는다고 하자. 주기적으로 어떤 수 x의 랭킹을 확인하고 싶을 때 해당 연산을 지원하는 자료구조와 알고리즘을 구현하라
- Peak과 Valley
11. 테스팅
테스팅과 관련된 질문들은 보통 다음 네 가지 범주 중 하나에 속한다.
- 실생활에서 접하는 객체를 테스트하라
- 소프트웨어 하나를 테스트하라
- 주어진 함수에 대한 테스트 코드를 작성하라
- 발생한 이슈에 대한 해결책을 찾아내라
면접관이 평가하는 것
- 큰 그림을 이해하고 있는가 : 소프트웨어가 지향하는 바가 무엇인지 정말로 이해하고 있는 사람인가? 테스트 케이스간의 우선순위를 적절히 매길 수 있는가?
- 퍼즐 조각을 제대로 맞추는 방법을 아는가 : 소프트웨어가 어떻게 동작하는지, 그리고 각 소프트웨어가 보다 더 큰 생태계의 일부로 어떻게 귀속되는지 이해하고 있는가?
- 조직화 : 문제에 구조적으로 접근하고 있는가, 아니면 생각나는 대로 아무 방법이나 질러보고 있는가?
- 실용성 : 실제로 적용 가능한 합리적인 테스트 계획을 세울 수 있나?
실제 세계에서 객체 테스트하기
클립을 테스트하려면 어떻게 하겠나? 라는 질문을 통해 살펴보자
- 사용자는 누구인가? 클립의 사용 목적은 무엇인가? 문제를 풀기전 해당 제품을 어떤 사용자가 어떤 목적으로 사용하게 될지 면접관과 의논해 봐야 한다.
- 어떤 use case가 있나? 유스케이스의 목록을 만들어두면 도움이 될 것이다. 이번 예에서는 “종이 다발을 망가뜨리지 않고 함께 묶어 놓는다”가 될 것이다.
- 한계 조건은? 한 번에 30장을 영구적 손상 없이 묶을 수 있다거나 30장에서 50장 정도는 약간의 손상이 있다거나 하는 것을 의미한다.
- 스트레스 조건과 장애 조건은? 문제가 없는 제품은 없다. 따라서 장애가 발생하는 조건을 분석하는 것도 여러분이 해야 하는 일이다. 어떤 종류의 문제를 심각하게 간주해야 하는지 등을 면접관과 이야기 해봐야 한다.
- 테스트는 어떻게 수행할 것인가? 테스트를 어떻게 수행할지 토론하는 것은 테스트와 관련된 세부사항을 이야기하는 것과 관련이 있다.
소프트웨어 테스팅
하나의 소프트웨어를 테스트하는 것은 실제 세계의 객체를 테스트하는 것과 아주 유사하다. 가장 큰 차이점은 소프트웨어의 경우 성능 테스트의 세부사항을 더 많이 강조한다는 것이다. 소프트웨어 테스팅의 두 가지 핵심적 측면은 다음과 같다.
- 수작업 테스트 vs 자동화된 테스트 : 이상적으로는 모든 것을 자동화하면 좋겠지만 불가능한 일이다. 컴퓨터는 일반적으로 살펴보라고 언급한 문제들만 인지하는 반면, 인간의 인지 능력은 특별히 검토된적이 없는 새로운 문제들을 밝혀낼 수도 있다.
- 블랙박스 테스트 vs 화이트박스 테스트 : 블랙박스 테스트의 경우 소프트웨어를 주어진 그대로 테스트해야 한다. 반면 화이트박스 테스트의 경우 그 내부의 개별 함수들을 프로그램적으로 접근하여 테스트할 수 있다.
소프트웨어 테스트에 적용할 수 있는 접근법을 처음부터 끝까지 하나씩 살펴보자
- 블랙박스 테스트를 하고 있는가 아니면 화이트박스 테스트를 하고 있는가? 면접관에게 어떤 테스트를 해야하는지 확인하라
- 누가 사용할 것인가? 왜 사용하는가?
- 어떤 유스케이스들이 있나?
- 한계 조건은? 유스케이스가 모호하게 정의되어 있다면 그게 무엇을 의미하는지 정확히 알아 낼 필요가 있다.
- 스트레스 조건과 장애 조건은? 소프트웨어에 장애가 발생한다면 그 장애는 어떤 모습이어야 하는가?
- 테스트 케이스는? 테스트 실행은 어떻게? 정확히 어떤 상황을 테스트하려고 하는가? 어떤 단계를 자동화할 수 있나? 사람이 개입해야 하는 부분은 어디인가? 자동화는 강력한 테스트를 가능하게 해주지만, 큰 문제를 일으킬 수도 있다. 따라서 수작업 테스트 또한 테스트 절차에 포함되어야 한다.
함수 테스트
함수 테스트는 가장 쉬운 종류의 테스트다. 보통 입력과 출력을 확인하는 테스트만 하면 되기 때문에 면접관과 길게 얘기할 것도 없고 모호한 부분도 적다. 그렇다고 대화의 중요성을 간과해서는 안 된다. 어떤 가정을 하건, 면접관과 그에 대해 대화를 해야 한다.
예) sort(int[] array)를 테스트하라는 문제를 받은 경우.
- 테스트 케이스 정의 :
- 정상적인 케이스 : 전형적인 입력에 대해 정확한 출력을 내는가? 여기서 발생할 수 있는 잠재적인 문제들에 대해 꼭 생각해보자.
- 극단적인 케이스 : 빈 배열을 인자로 넘기면 어떻게 되는가?
- 널 입력, 잘못된 입력 : 입력이 잘못 주어졌을 때 코드가 어떻게 동작해야 하는지 고려해 봐야 한다.
- 특수한 입력 : 특수한 패턴의 입력도 때로 주어질 수 있다. 이미 정렬된 배열이 입력으로 주어지면 어떻게 되나? 혹은 아예 역순으로 정렬된 배열이 주어진다면?
- 예상되는 결과를 정의하라
- 테스트 코드를 작성하라
문제 해결에 관한 문제
이미 있는 장애를 어떻게 디버깅하고 해결할 것인지를 설명하라는 문제도 출제된다. 이런 경우도 다른 문제와 마찬가지로 구조적으로 접근해서 해결할 수 있다.
- 시나리오를 이해하라 : 상황을 가능한 한 정확하게 이해할 수 있도록 많은 질문을 던져라
- 문제를 쪼개라 : 문제를 테스트 가능한 단위로 분할할 순서다.
- 구체적이고 관리 가능한 테스트들을 생성하라 : 고객에게 뭘 해달라는 지시를 내릴 순 없을 것이다. 그러므로 여러분이 본인 컴퓨터에서 반복 검증할 수 있는 테스트를 생성해야 한다.
면접 문제
- 오류 : 다음 코드에서 오류를 찾아내라
- 무작위 고장 : 실행하면 죽어버리는 프로그램의 소스코드가 있다. 디버거에서 열 번 실행해 본 결과, 같은 지점에서 죽는 일은 없었다. 단일 스레드 프로그램이고, C의 표준 라이브러리만 사용한다. 오류들을 각각 어떻게 테스트해 볼 수 있겠는가?
- 체스 테스트
- No 테스트 도구 : 테스트 도구를 사용하지 않고 웹 페이지에 부하 테스트를 실행하려면 어떻게 할 수 있겠는가?
- 펜 테스트 : 펜을 어떻게 테스트하겠는가?
- ATM 테스트 : 분산 은행 업무 시스템을 구성하는 ATM을 어떻게 테스트하겠는가?
12. C와 C++
13. 자바
언어 자체 질문에 대한 접근법
- 예제 시나리오를 만들어 보고 어떻게 전개되어야 하는지 자문해 보라
- 다른 언어에선 이 시나리오를 어떻게 처리할 것인지 자문해 보라
- 프로그래밍 언어를 설계하는 사람이라면 이 상황을 어떻게 설계할 것인지 생각해 보라 어떤 선택이 어떤 결과로 이어지는가?
면접관들은 반사적으로 답을 내놓는 지원자만큼이나 답을 유도해 낼 수 있는 지원자에게 좋은 인상을 갖는다.
오버로딩 vs 오버라이딩
오버로딩은 두 메서드가 같은 이름을 갖고 있으나 인자의 수나 자료형이 다른 경우를 지칭한다.
오버라이딩은 상위 클래스의 메서드와 이름과 용례가 같은 함수를 하위 클래스에 재정의하는 것을 말한다.
컬렉션 프레임워크
자바의 컬렉션 프레임워크는 아주 유용하다.
- ArrayList : ArrayList는 동적으로 크기가 조절되는 배열이다. 새 원소를 삽입하면 크기가 늘어난다.
- Vector : ArrayList와 비슷하지만 동기화되어 있다는 차이가 있다.
- LinkedList
- HashMap : HashMap 컬렉션은 면접이나 실제 상황 가릴 것 없이 광범위하게 사용된다.
면접 문제
- Private 생성자 : 상속 관점에서 생성자를 private로 선언하면 어떤 효과가 있나?
- finally에서의 반환 : try-catch-finally 의 try 블록에서 return 문을 넣어도 실행되는가?
- final과 그 외 : final, finally, finalize의 차이는?
- 제네릭 vs 템플릿 : 자바 제네릭과 C++ 템플릿의 차이를 설명하라
- TreeMap, HashMap, LinkedHashMap : 각 차이를 설명하고 언제 무엇을 사용하는 것이 좋은지 예를 들어 사용하라
- 객체 리플렉션 : 자바의 객체 리플렉션을 설명하고, 이것이 유용한 이유를 설명하라
- 람다 표현식 : Country라는 클래스의 getContinent()와 getPopulation()이 라는 메서드가 있다. 대륙의 이름과 국가의 리스트가 주어졌을 때 주어진 대륙의 총 인구수를 계산하는 메서드를 작성하라
- 람다 랜덤 : 람다 표현식을 사용해서 임의의 부분집합을 반환하는 함수를 작성하라
14. 데이터베이스
SQL 문법과 그 변종들
묵시적 JOIN과 명시적 JOIN
비정규화 vs 정규화 데이터베이스
정규화 데이터베이스는 중복을 최소화하도록 설계된 데이터베이스를 말한다. 비정규화 데이터베이스는 읽는 시간을 최적화하도록 설계된 데이터베이스를 말한다.
전형적인 정규화 데이터베이스의 경우 외래키를 갖는 컬럼이 있을 것이다. 이 설계의 장점은 데이터베이스에 데이터를 한 번만 저장해도 된다는 점이다. 하지만 상당수 일상적 질의를 처리하기 위해 JOIN을 많이 하게된다는 단점이 있다.
대신 비정규화 데이터베이스에서는 데이터를 중복해서 저장할 수 있다. 같은 질의를 자주 반복해서 한다는 사실을 미리 알고 있으면, 정보를 중복해서 다른 테이블에 저장할 수도 있다. 비정규화는 높은 규모의 확장성을 실현하기 위해 자주 사용되는 기법이다.
SQL 문
249~251p
소규모 데이터베이스 설계
- 모호성 처리 : 데이터베이스에 관계된 문제에는 의도적이든 아니든 모호한 부분이 내포되어 있다. 설계를 시작하기 전에 무엇을 설계해야 하는지 이해해야 한다. 따라서 모호한 부분이 있다면 면접관과 논의해야 한다.
- 핵심 객체 정의 : 이 시스템의 핵심 객체가 무엇인지 살펴봐야 한다. 보통 핵심 객체 하나 당 테이블을 사용한다.
- 관계 분석 : 핵심 객체의 윤곽을 잡고 나면 어떻게 테이블을 설계해야 할지 감을 잡을 수 있을 것이다. 테이블끼리의 관계가 어떻게 되는지 분석해야한다.
- 행위 조사 : 세부적인 부분을 채워 넣는다. 흔하게 수정될 작업들을 살펴보고 관련된 데이터를 어떻게 저장하고 가져올 것인지 이해해야 한다.
대규모 데이터베이스 설계
대규모의 규모 확장성이 높은 데이터베이스를 설계할 때에 JOIN 연산은 일반적으로 아주 느리다고 간주해야 한다. 따라서 데이터를 비정규화해야 한다.
면접 문제
- 하나 이상의 집 : 하나 이상의 집을 대여한 모든 거주자의 목록을 구하는 SQL 질의문을 작성하라
- Open 상태인 Request : 모든 건물 목록과 Status가 Open인 모든 Request의 개수를 구하라
- Request를 Close로 바꾸기
- JOIN : 서로 다른 종류의 JOIN은 어떤 것들이 있는가? 어떻게 다르고, 어떤 상황에서 어떤 JOIN과 어울리는지 설명하라
- 비정규화 : 비정규화란 무엇인가? 장단점을 설명하라
- 객체-관계 다이어그램 : 회사, 사람, 직원으로 구성된 데이터베이스의 ERD를 그려라
- 성적 데이터베이스 설계 : 학생들의 성적을 저장하는 간단한 데이터베이스를 생각해보고 설계하라, 그리고 성적이 우수한 학생 목록을 반환하는 SQL 질의문을 작성하라.
15. 스레드와 락
대기업 회사에서 스레드로 알고리즘을 구현하라는 문제를 출제하는 일이 흔하지는 않지만 스레드, 특히 교착상태에 대한 일반적인 이해도를 평가하기 위한 문제는 어떤 회사든 상대적으로 자주 출제하는 편이다.
자바의 스레드
자바의 모든 스레드는 java.lang.Thread 클래스의 객체에 의해 생성되고 제어된다. 자바에서 스레드를 구현하는 방법은 다음과 같다.
- java.lang.Runnable 인터페이스를 구현하기 : Runnable 인터페이스를 구현하는 클래스를 만들고, Thread 타입의 객체를 만들때 Thread 생성자에 Runnable 객체를 인자로 넘긴다. 그리고 Thread 객체의 start() 메서드를 호출한다.
- java.lang.Thread 클래스를 상속받기 : Thread 클래스를 상속받아서 스레드를 만들게 되면 항상 run() 메서드를 오버라이드해야 하며, 하위 클래스의 생성자는 상위 클래스의 생성자를 명시적으로 호출해야 한다.
스레드를 생성할 때 Runnable 인터페이스를 구현하는 것이 더 선호된다. 이유는 자바는 다중 상속을 지원하지 않아 Thread 클래스를 상속하게 되면 다른 클래스를 상속받을 수 없기 때문이다.
동기화와 락
어떤 프로세스 안에서 생성된 스레드들은 같은 메모리 공간을 공유하게 된다. 이것은 장점일 수 있으나 두 스레드가 같은 자원을 동시에 변경하는 경우에 문제가 된다. 자바는 공유 자원에 대한 접근을 제어하기 위한 동기화 방법을 제공한다.
동기화된 메서드
통상적으로 synchronized 키워드를 사용할 때는 공유 자원에 대한 접근을 제어한다. 이 키워드는 메서드에 적용할 수도 있고, 특정한 코드 블록에 적용할 수도 있다.
1
2
3
4
5
6
7
8
9
10
public class MyObject {
public synchronized void foo (String name) {
try {
System.out.printin("Thread " + name + ", foo(): starting");
Thread. sleep (3000);
System. out.println("Thread ' + name + ". foo (): ending");
} catch (InterruptedException exc) {
System.out.println("Thread " + name + ": interrupted.");
}
}
동기화된 블록
1
2
3
4
5
6
7
public class MyObiect {
public void foo(String name) {
synchronized (this) {
//...
}
}
}
락
좀 더 세밀하게 동기화를 제어하고 싶을 때는 락을 사용한다. Lock을 공유 자원에 붙이면 해당 자원에 대한 접근을 동기화할 수 있다. 스레드가 해당 자원에 접근하려면 그 자원에 붙어있는 락을 획득해야 한다. 특정 시점에 락을 쥐고 있을 수 있는 스레드는 하나뿐이다.
교착상태와 교착상태 방지
교착상태란 첫 번째 스레드는 두 번째 스레드가 들고 있는 객체의 락이 풀리기를 기다리고 있고, 두 번째 스레드 역시 첫 번째 스레드가 들고 있는 객체의 락이 풀리기를 기다리는 상황을 일컫는다. 모든 스레드가 락이 풀리고 있길 기다리는 ‘무한대기 상태’에 빠지게 된다. 교착상태가 발생하기 위해서는 다음의 조건을 모두 충족해야 한다.
- 상호 배제 : 한 번에 한 프로세스만 공유 자원을 사용할 수 있다.
- 들고 기다리기 : 공유 자원에 대한 접근 권한을 갖고 있는 프로세스가, 그 접근 권한을 양보하지 않은 상태에서 다른 자원에 대한 접근 권한을 요구할 수 있다.
- 선취 불가능 : 한 프로세스가 다른 프로세스의 자원 접근 권한을 강제로 취소할 수 있다.
- 대기 상태의 사이클 : 두 개 이상의 프로세스가 자원 접근을 기다리는데, 그 관계에 사이클이 존재한다.
교착상태를 방지하기 위해선 이 조건들 가운데 하나를 제거하면 된다. 대부분 교착상태 방지 알고리즘은 4번 조건을 막는데 초점이 맞춰져 있다.
면접 문제
- 프로세스 vs 스레드 : 두개의 차이는?
- 문맥 전환 : 문맥 전환에 소요되는 시간을 측정하려면?
- 철학자의 만찬
- 교착상태 없는 클래스 : 교착상태에 빠지지 않는 경우에만 락을 제공해주는 클래스를 설계해보라
- 순서대로 호출
- 동기화된 메서드 : 동기화된 A 메서드, 일반 B 메서드가 구현된 클래스가 있을 때, 같은 프로그램에서 실행되는 스레드가 두 개 존재할 때 A를 동시에 실행할 수 있는가? A와 B는 동시에 실행될 수 있는가?
- FizzBuzz
16. 중간 난이도 연습문제
- 숫자 교환 : 임시 변수를 사용하지 않고 숫자를 교환하는 함수를 작성하라
- 단어 출현 빈도 : 어떤 책에서 나타난 단어의 출현 빈도를 계산하는 메서드를 설계하라
- 교차점 : 시작점과 끝점으로 이루어진 선분 두 개가 주어질 때, 이 둘의 교차점을 찾는 프로그램을 작성하라
- 틱-택-토의 승자 : 승자를 알아내는 알고리즘을 설계하라
- 계승의 0 : n!의 계산 결과에서 마지막에 붙은 연속된 0의 개수를 계산하는 알고리즘을 작성하라
- 최소의 차이 : 두 개의 정수 배열이 주어져 있다. 각 배열에서 숫자를 하나씩 선택했을 때 두 숫자의 차이가 최소인 값을 출력하라
- 최대 숫자 : 주어진 두 수의 최댓값을 찾는 메서드를 작성하라 (if-else나 비교 연산자는 사용할 수 없다.)
- 정수를 영어로 : 정수가 주어졌을 때 이 숫자를 영어 구문으로 표현해주는 프로그램을 작성하라
- 연산자 : 덧셈 연산자만을 사용하여 정수에 대한 곱셈, 뺄셈, 나눗셈 연산을 수행하는 메서드를 작성하라
- 살아 있는 사람 : 사람의 태어난 연도와 사망한 연도가 리스트로 주어졌을 때 가장 많은 사람이 동시에 살았던 연도를 찾는 메서드를 작성하라
- 다이빙 보드 : 다량의 널빤지를 이어 붙여서 다이빙 보드를 만들려고 한다. 널빤지는 길이가 긴 것과 짧은 것 두 가지 종류가 있는데, 정확히 K개의 널빤지를 사용해서 다이빙 보드를 만들어야 한다. 가능한 다이빙 보드의 길이를 모두 구하는 메서드를 작성하라.
- XML 인코딩 : XML 요소가 주어졌을 때, 해당 요소를 인코딩한 문자열을 출력하는 메서드를 작성하라.
- 정사각형 절반으로 나누기 : 2차원 평면 위에 정사각형 두 개가 주어졌을 때, 이들을 절반으로 가르는 직선 하나를 찾으라
- 최고의 직선 : 2차원 평면 위에서 점이 여러 개 찍혀 있을 때 가장 많은 수의 점을 동시에 지나는 직선을 구하라
- Master Mind
- 부분 정렬 : 정수 배열이 주어졌을 때, m부터 n까지의 원소를 정렬하기만 하면 배열 전체가 정렬되는 인덱스 m과 n을 찾으라.
- 연속 수열 : 정수 배열이 주어졌을 때 연속한 합이 가장 큰 수열을 찾고 그 합을 반환하라
- 패턴 매칭 : 패턴 문자열과 일반 문자열 두 개가 주어져있다. a와 b로 이루어진 패턴 문자열은 일반 문자열을 표현하는 역할을 한다. 일반 문자열이 패턴 문자열 과 일치하는지 판단하는 메서드를 작성하라.
- 연못 크기 : 대륙의 해발고도를 표현한 정수형 배열이 주어졌다. 여기서 0은 수면을 나타내고, 연못은 수직, 수평, 대각선으로 연결된 수면의 영역을 나타낸다. 연못의 크기는 연결된 수면의 개수라고 했을 때, 모든 연못의 크기를 계산하는 메서드를 작성하라
- T9
- 합의 교환 : 정수형 배열 두 개가 주어졌을 때, 각 배열에서 원소를 하나씩 교환해서 두 배열의 합이 같아지게 만들라
- 랭턴 개미
- Rand5로부터 Rand7 : rand5()를 사용해서 rand7() 메서드를 구현하라. 즉, 0 부터 4까지 숫자 중에서 임의의 숫자를 반환하는 메서드를 이용해서 0부터 6까지의 숫자 중에서 임의의 숫자를 반환하는 메서드를 작성하라.
- 합이 되는 쌍 : 정수형 배열이 주어졌을 때, 두 원소의 합이 특정 값이 되는 모든 원소 쌍을 출력하는 알고리즘을 설계하라
- LRU 캐시 : 가장 오래된 아이템을 제거하는 최저 사용 빈도 캐시를 설계하고 구현하라
- 계산기 : 양의 정수 +, -, *, / 로 구성된 수식을 계산하는 프로그램을 작성하라
17. 어려운 연습문제
- 덧셈 없이 더하기 : 두 수를 더하는 함수를 작성하라. 단, +를 비롯한 어떤 연산자도 사용할 수 없다.
- 섞기 : 카드 한 벌을 완벽히 섞는 메서드를 작성하라 (완벽의 의미는 카드 한 벌을 섞는 방법이 52가지가 있는데 이 각각이 전부 같은 확률로 나타날 수 있어야 한다는 뜻이다.)
- 임의의 집합 : 길이가 n인 배열에서 m개의 원소를 무작위로 추출하는 메서드를 작성하라. 단, 각 원소가 선택될 확률은 동일해야 한다.
- 빠진 숫자 : 배열 A에는 0부터 n까지의 숫자 중 하나를 뺀 나머지가 모두 들어 있다. 배열 A에서 빠진 숫자가 무엇인지 확인하는 코드를 작성하라. O(n)시간에 할 수 있겠는가?
- 문자와 숫자 : 문자와 숫자로 채워진 배열이 주어졌을 때 문자와 숫자의 개수가 같으면서 가장 긴 부분 배열을 구하라
- 숫자 2세기 : 0부터 n까지의 수를 나열했을 때 2가 몇 번이나 등장했는지 세는 메서드를 작성하라
- 아기 이름 : 정부는 매년 가장 흔한 아기 이름 10,000명과 그 이름의 빈도수를 발표한다. 하지만 아기 이름의 철자가 다르면 빈도수를 세는 데 문제가 될 수 있다. 예를 들어 John과 Jon은 실제로는 같은 이름이지만 다르게 분류되는 것이다. 이름/빈도수 리스트와 같은 이름의 쌍이 리스트로 주어졌을 때 실제 빈도수의 리스트를 출력하는 알고리즘을 작성하라.
- 서커스 타워 : 단원의 키와 몸무게가 주어졌을 때 최대로 쌓을 수 있는 인원수를 계산하는 메서드를 작성하라.(어깨 위에 올라서는 사람은 아래에 있는 사람보다 가벼우면서 키도 작아야 한다.)
- k번째 배수 : 소인수가 3,5,7로만 구성된 숫자 중 k번째 숫자를 찾는 알고리즘을 설계하라
- 다수 원소 : 다수 원소란 배열에서 그 개수가 절반 이상인 원소를 말한다. 양의 정수로 이루어진 배열이 주어졌을 때 다수 원소를 찾으라. 다수 원소가 없다면 -1을 반환하라. 알고리즘은 O(N) 시간과 O(1) 공간 안에 수행되어야 한다.
- 단어 간의 거리 : 단어가 적혀 있는 아주 큰 텍스트 파일이 있다. 단어 두 개가 입력으로 주어졌을 때, 해당 파일 안에서 그 두 단어 사이의 최단거리를 구하는 코드를 작성하라. 같은 파일에서 단어간 최단 거리를 구하는 연산을 여러 번 반복한다고 했을 때 어떤 최적화 기법을 사용할 수 있겠는가?
- 공백 입력하기 : 긴 문서를 편집하다가 실수로 공백과 구두점을 지우고, 대문자를 전부 소문자로 바꿔 버렸다. 예) “I reset the computer. It still didn’t boot!”과 같은 문장이 “iresetthecomputeritstilldidntboot!” 로 바뀐 것이다. 사전과 문서가 주어졌을 때 단어들을 원래대로 분리하는 최적의 알고리즘을 설계하라
- 가장 작은 숫자 K개 : 배열에서 가장 작은 숫자 K개를 찾는 알고리즘을 설계하라
- 가장 긴 단어 : 주어진 단어 리스트에서 다른 단어들을 조합하여 만들 수 있는 가장 긴 단어를 찾는 프로그램을 작성하라
- 마사지사 : 인기 있는 마사지사가 있다. 마사지 사이에 15분간 휴식이 필요하므로 마사지 예약이 연달아 들어온다면 그 중에서 어떤 예약을 받을지 선택해야 한다. 연달아 들어온 마사지 예약 리스트가 주어졌을 때(모든 예약 시 간은 15분의 배수이며 서로 겹치지는 않고 한번 예약이 되면 변경이 불가능 하다), 총 예약 시간이 가장 긴 최적의 마사지 예약 순서를 찾으라.
- 다중 검색 : 문자열 s와 s보다 짧은 길이를 갖는 문자열로 이루어진 배열 T가 주어졌을 때, T에 있는 각 문자열을 s에서 찾는 메서드를 작성하라
- 가장 짧은 초수열 : 작은 길이의 배열과 그보다 긴 길이의 배열 두 개가 주어졌다. 길이가 긴 배열에서 길이가 작은 배열의 원소를 모두 포함하면서 길이가 가장 짧은 부분배열을 찾으라
- 빠진 숫자 찾기 : 1부터 N까지 숫자 중에서 하나를 뺀 나머지가 정확히 한 번 씩 등장하는 배열이 있다. 빠진 숫자를 O(N) 시간과 O(1) 공간에 찾을 수 있겠는가? 만약 숫자 두 개가 빠져 있다면 어떻게 찾겠는가?
- 연속된 중간 값 : 임의의 수열이 끊임없이 생성되고 이 값이 어떤 메서드로 전달된다고 할 때, 새로운 값이 생성될 때마다 현재까지의 중간값을 찾고 그 값을 유지하는 프로그램을 작성하라
- 막대 그래프의 부피 : 누군가가 히스토그램 위에서 물을 부었을 때, 이 그래프가 저장할 수 있는 물의 양을 계산하는 알고리즘을 설계하라
- 단어 변환 : 사전에 등장하는 길이가 같은 단어 두 개가 주어졌을 때, 한 번에 글자 하나만 바꾸어 한 단어를 다른 단어로 변환하는 메서드를 작성하라
- 최대 검은색 정방행렬 : 정방형의 행렬이 있다. 이 행렬의 각 셀은 검은색이거나 흰색이다. 네 가장자리가 전부 검은색인 최대 부분 정방행렬을 찾는 알고리즘을 설계하라
- 최대 부분 행렬 : 양의 정수와 음의 정수로 이루어진 N X N 행렬이 주어졌을 때 모든 원소의 합이 최대가 되는 부분 행렬을 찾는 코드를 작성하라
- 단어 직사각형 : 백만 개의 단어 목록이 주어졌을 때, 각 단어의 글자들을 사용하여 만들 수 있는 최대 크기 직사각형을 구하는 알고리즘을 설계하라
- 드문드문 유사도