
언어란 무엇인가
언어는 편의를 제공하기 위한 지름길이다. 모든 언어의 뜻은 기호의 집합으로 인코딩 된다. 하지만 의미를 기호로 인코딩하는 것으로 충분하지 않다. 언어가 제대로 작동하려면 의사소통하는 당사자들이 모두 같은 문맥을 공유해서 같은 기호에 같은 뜻을 부여할 수 있어야 한다.
문자 언어
문자 언어는 기호를 나열한 것이다. 기호를 정해진 순서대로 나열하면 단어를 만들 수 있다. 언어마다 기호와 기호 유형이 달라질 수 있고 순서도 다를 수 있다.
다음의 구성 요소가 문자 언어의 틀을 이루고 컴퓨터 언어에서도 마찬가지이다.
- 기호가 들어갈 상자
- 상자에 들어갈 기호
- 상자의 순서
비트
자연어에서 상자는 ‘문자’라고 부르고 컴퓨터에서는 ‘비트 bit’라고 부른다. 비트는 binary + digit가 합쳐진 말이다. 비트는 2진법을 사용하고 이는 모스 부호의 점(.)과 선(-)처럼 두 가지 기호 중 하나만 담을 수 있다는 뜻이다. 자연어와 마찬가지로 기호의 순서가 중요하다.
예) A (.-), B(-…), C(-.-.)
논리 연산
비트 사용법 중 하나는 날씨가 추운가? 같은 예(true)/아니요(false) 질문에 대한 답을 표현하는 것이다. 자연어에서는 예/아니요 구절을 엮어 한 문장으로 만드는 경우가 자주 있다. ‘밖에 비가 내리고 있거나 춥다면 코트를 입어라’ 이처럼 다른 비트들이 표현하는 내용으로부터 새로운 비트를 만들어내는 이런 동작을 ‘논리 연산’이라고 한다.
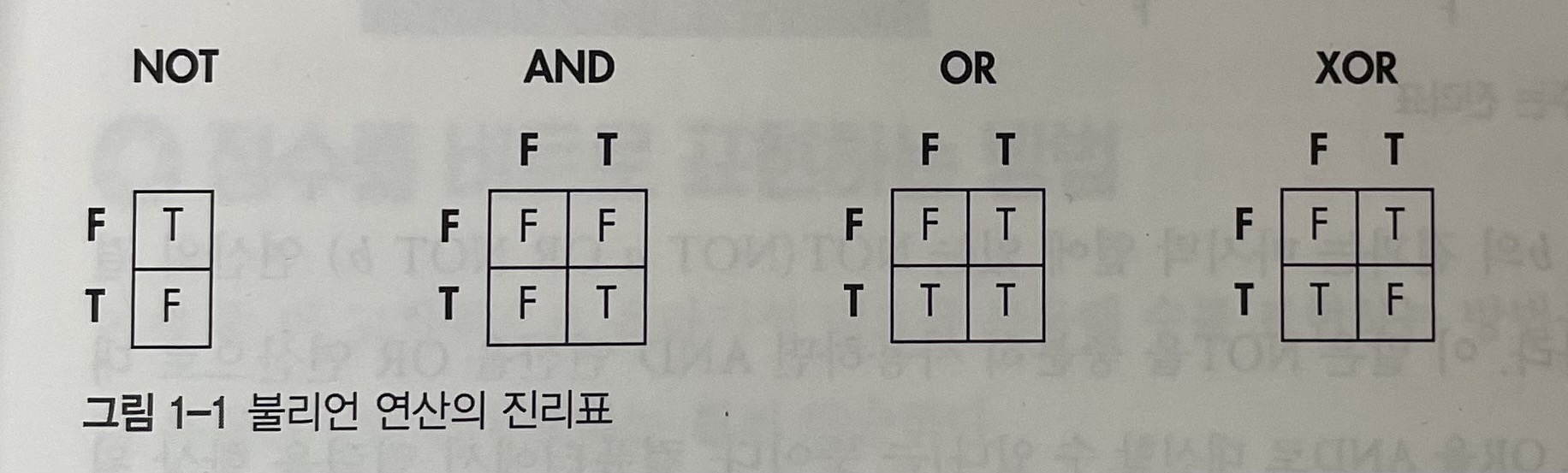
1) 불리언 대수
비트에 대해 사용할 수 있는 연산 규칙의 집합으로 기본적으로 NOT, AND, OR 세 가지의 연산자가 있다.
- NOT : 논리적 반대를 의미한다. 거짓인 비트에 NOT을 하면 참이 되고 참인 비트에 NOT을 하면 거짓이 된다.
- AND : 둘 이상의 비트에 작용한다. 모든 비트가 참인 경우 AND 연산의 결과도 참이다.
- OR : 둘 이상의 비트에 작용한다. 어느 한 비트라도 참이라면 OR 연산의 결과도 참이다.
- XOR : 첫 번째 비트와 두 번째 비트가 다른 값인 경우에만 참이 된다.
2) 드로르간의 법칙
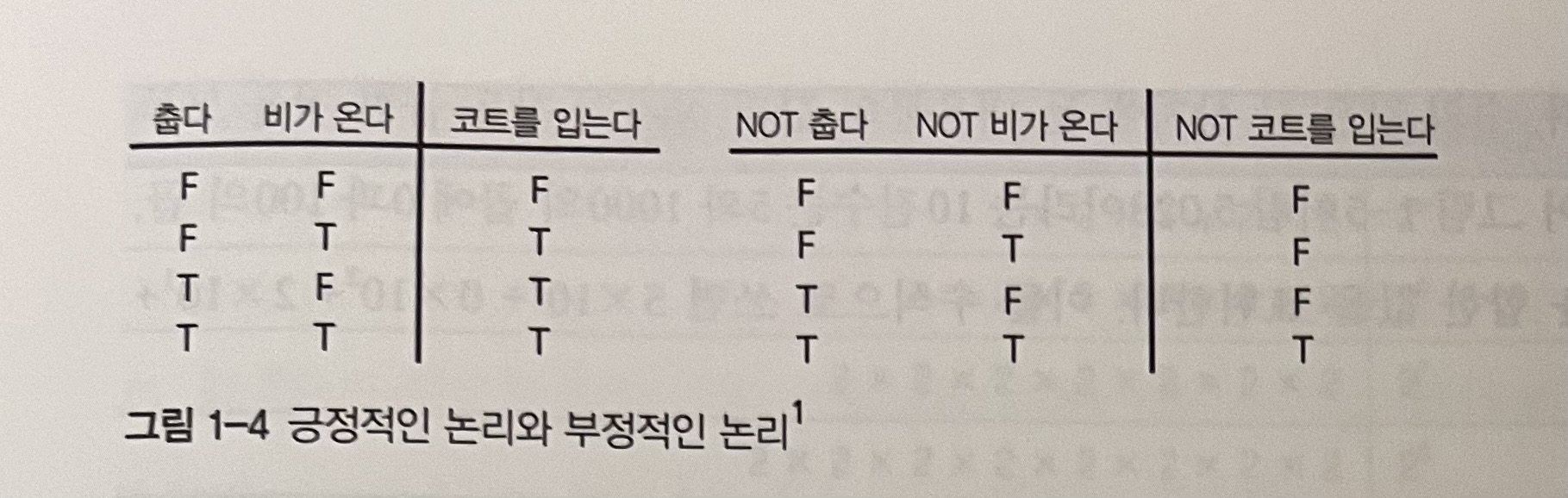
불리언 대수에 적용할 수 있는 법칙으로 a AND b == NOT(NOT a OR NOT b) 이다. 즉 NOT을 충분히 사용하면 AND 연산을 OR 연산으로 대신할 수 있다는 의미이다. 긍정적인 논리에 더해 부정적인 논리를 기술하는 명제를 사용할 때 드모르간 법칙을 활용할 수 있다.
정수를 비트로 표현하는 방법
1) 양의 정수 표현
우리는 보통 10진수를 사용한다. 10진수 체계에서는 10가지 기호인 숫자를 상자에 담을 수 있고 이때 오른쪽에서 왼쪽으로 상자가 쌓여진다. 맨 오른쪽에서부터 일의 자리, 십의 자리, 백의 자리 등등의 이름이 붙는다. 각 이름은 10의 거듭제곱에 해당한다.
예) 5028을 계산하면 => 5 * 1000 + 0 * 100 + 2 * 10 8 * 1
비트를 사용할 때도 비슷하게 동작하는데 각 상자에 사용할 수 있는 기호는 1과 0 두가지 밖에 없다. 따라서 각 상자의 자릴수는 2의 거듭제곱이며 2진수 체계는 10을 밑으로 하지 않고 2를 밑으로 하는 수 체계다.
예) 
2진수에서 가장 오른쪽의 비트를 가장 작은 유효비트(LSB)라고 부르고, 가장 왼쪽의 비트를 가장 큰 유효비트(MSB) 라고 부른다. 그래서 LSB를 변경하면 2진수의 값이 가장 작게 변경되고 MSB의 비트를 변경하면 2진수의 값이 가장 크게 변한다.
2) 2진수 덧셈
2진수에서도 덧셈 연산을 할 때 10진수 처럼 각 비트를 LSB에서 MSB쪽으로 더하며 결과가 1보다 크면 다음 자리에 1을 올린다. 덧셈 규칙을 논리 연산을 사용해 다음과 같이 표현할 수도 있다.
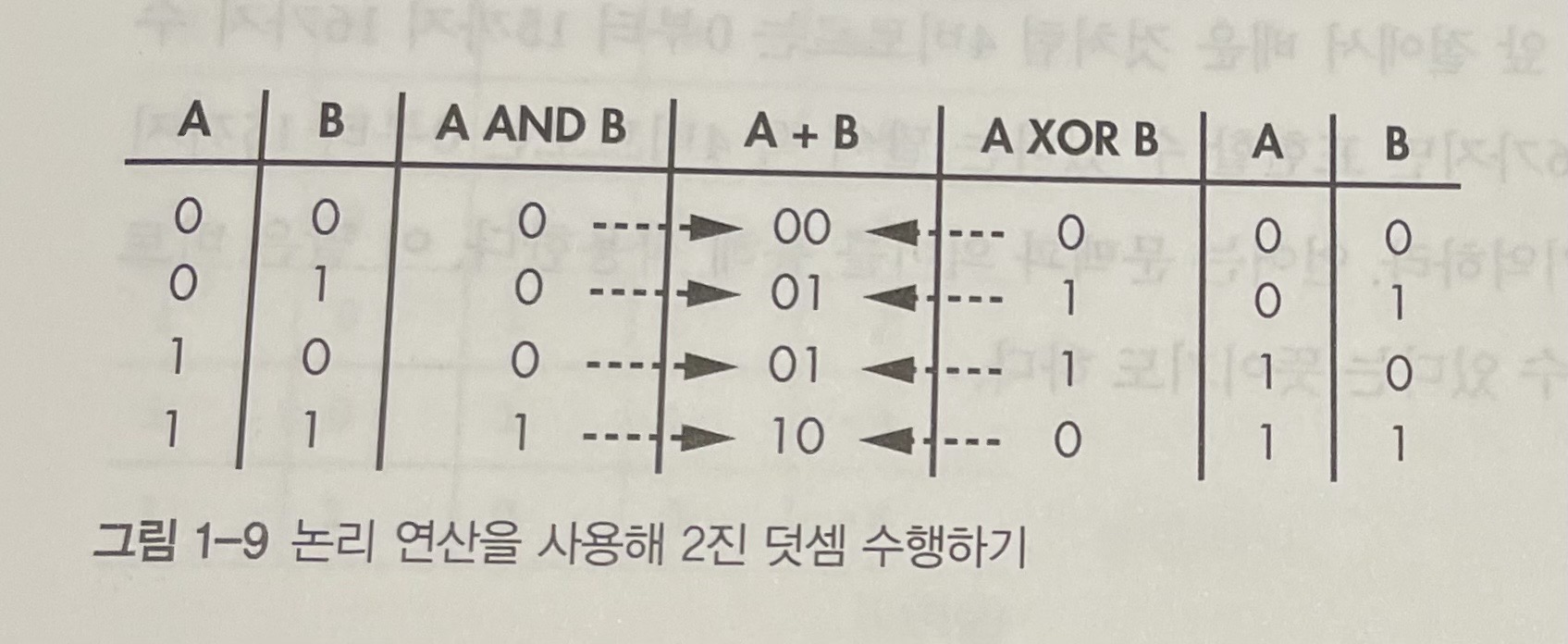
두 비트를 서로 더한 결과는 두 비트를 XOR 한 값과 같고, 올림은 두 비트를 AND한 값과 같다. 덧셈 결과가 비트의 개수로 표현할 수 있는 범위를 벗어나면 ‘오버플로’가 발생한다.(MSB에서 올림이 발생했다는 뜻) 예) 1001 과 1000을 더한 결과는 10001이다. 하지만 MSB 왼쪽에 사용할 수 있는 비트가 없기 때문에 결과가 0001이 된다.
컴퓨터에는 조건코드 레지스터라는 것이 있어 몇가지 정보 중 오버플로 비트가 있고, 이 비트에는 MSB에서 발생한 올림값이 들어간다. 따라서 이 비트 값을 보면 오버플로가 발생했는지 알 수 있다. (반대로 MSB 위쪽에서 1을 빌려오는 경우 언더플로라고 한다.)
3) 음수 표현
- 부호와 크기 : 음수와 양수를 구별하기 위해서 흔히 ‘부호’를 사용한다. 이 부호에는 비트를 하나 사용해서 표현하는데 가장 왼쪽 비트를 부호피트로 사용한다. 부호비트가 0이면 양수로 취급하고, 1이면 음수로 취급한다. 이런한 방법을
부호와 크기 표현법이라고 말한다. 부호화 크기 표현법은 널리 쓰이지 못하고 있는데 이는 비트를 구성하는데 비용이 낭비되고, XOR, AND를 통한 덧셈 계산을 사용할 수 없다. - 1의 보수 : 양수의 모든 비트를 뒤집는 방법이다. NOT 연산을 통해 보수를 얻는다. 예) 0111(+7) -> 1000(-7) 1의 보수 표현법도 덧셈이 쉽지 않다. MSB쪽에서 올림이 발생한 경우 LSB 쪽으로 올림을 전달한다. 이를 순환 올림이라 부른다.
- 2의 보수 : 어떤 수의 비트를 뒤집고 1을 추가하면 음수를 얻는다. 예) 0001(+1) 을 뒤집으면 1110이고 여기에 1을 더하면 1111(-1)이 된다.
**우리가 같은 숫자로 이뤄진 수를 보더라도 문맥에 따라 표현하는 값이 달라질 수 있다는 점을 꼭 염두해둬야 한다. 예를 들어 2진수 1111은 2의 보수에서는 -1이고, 부호와 크기 표기로는 -7, 1의 보수에서는 -0이다. 따라서 사용하는 표현법을 반드시 알고 있어야 한다.
실수를 표현하는 방법
실수 표현은 밑이 10인 실수에는 10진 소수점이 포함되고, 밑이 2인 경우 2진 소수점을 표현할 방법이 필요하다. 여기서도 정수와 마찬가지로 문맥에 따라 실수를 표현하는 방법이 달라질 수 있다.
1) 고정소수점 표현법
예를 들어 4비트가 있다면 그중 2비트는 2진 소수점의 오른쪽에 있는 분수들을 표현하는데 사용하고 2비트는 왼쪽에 있는 숫지들을 표현하는 데 쓸 수 있다. 소수점의 위치가 항상 일정하기 때문에 이런 방식을 ‘고정소수점 표현법’이라고 한다. 다만 2진수의 경우 1/2, 1/4 등 2의 거듭제곱을 분모로 사용한다는 점이 10진수와 다르다.
2) 부동소수점 표현법
과학적 표기법을 2진수에 적용한다. 과학적 표기법에는 0.0012 대신 1.2 X 10⁻³이라고 쓴다. 2진법으로 표기할 때는 10이 아닌 2를 밑으로 한다는 점이 10진법과 다르다. 즉 가수 부분은 2진 소수, 지수 부분은 2의 거듭제곱 횟수를 표현한다. 그리고 이러한 표기법을 부동소수점 표현법이라고 부른다.
여기서 지수의 밑인 2라는 숫자를 비트로 표현할 필요는 없다. 부동소수의 정의상 밑 2는 항상 정해져 있다. 부동소수점 표현법은 지수와 가수를 분리함으로써 수를 표현할 때 필요한 0을 모두 저장하지 않고도 큰 수나 작은 수를 표현할 수 있다.
3) IEEE 부동소수점 수 표준
부동소수점 수 시스템은 컴퓨터에서 계산을 수행할 때 실수를 표현하는 표준 방법이다. 똑같은 비트를 사용하더라도 정밀도를 높이기 위한 트릭으로 정규화가 있다. 정규화는 가수를 조정해서 맨 앞에 0이 없게 만드는 것이다. 두 번째 트릭은 가수의 맨 왼쪽 비트가 1이라는 사실을 알고 있으므로 이를 생략하고 이로 인해 가수에 1비트를 더 사용할 수 있다.
IEEE 754는 2가지 부동소수점 수가 자주 쓰인다. 1)기본 정밀도 부동소수점 수 2)2배 정밀도 부동소수점 수 이다. 두 가지를 살펴보면 2배 정밀도 수가 기본 정밀도 수보다 지수가 3비트 더 크고, 지수의 범위는 8배가 더 크다. 또 가수가 29비트 더 커서 정밀도도 훨씬 더크다. 대신 비트를 2배나 더 많이 사용한다는 비용을 지불하고 얻은 것이다.
IEEE 754에서 편리한 점은 0으로 나눴을 때 생길 수 있는 양의 무한대나 음의 무한대를 표현하는 비트 패턴 등 여러 가지 특별한 비트 패턴을 제공하고, 그 중 수가 아님을 뜻하는 NaN을 표현하는 특별한 값도 있다.
2진 코드화한 10진수 시스템
2진 코드화한 10진수(BCD)는 4비트를 사용해 10진 숫자를 하나 표현한다. 예) 12를 2진수로 표현하면 1100, BCD로 표현하면 0001 0010 이다. 오래된 컴퓨터에서는 BCD 수를 처리하는 방법을 알고 있지만 이런 시스템은 더 이상 주류에 남아있지 않다.
2진수를 다루는 쉬운 방법
1) 8진 표현법
8진이라는 말은 밑이 8이라는 뜻이다. 8진 표현법은 2진수 비트들을 3개씩 그룹으로 묶는 아이디어다.
예)2진수의 8진 표현법 : 100/101/110/001/010/100 => 4/5/6/1/2/4
2) 16진 표현법
2진수는 10진수에서 두 가지 0, 1을 사용하고 8진수는 숫자 8개만 사용한다. 하지만 16진수는 숫자 하나를 표현하려면 우리가 갖고 있는 10가지 숫자만으로는 충분하지 않다. 그래서 abcdef 기호가 10부터 15까지의 숫자를 표현한다고 믿기로 했다. 여기서는 비트를 4개씩 그룹으로 나눈다.
예)2진수의 16진 표현법 : 1101/0011/1111/1100/0001 => d/3/f/c/1
3) 프로그래밍 언어의 진법 표기법
프로그래밍에서는 0으로 시작하면 8진수 예)017 => 10진수로 15, 1~9사이의 숫자는 10진수 예)123, 0x가 붙으면 16진수 예)0x12f => 10진수로 303이다.
비트 그룹의 이름
비트는 너무 작아서 기본 담위로 사용하기에는 유용성이 떨어진다. 따라서 세계적으로 8비트 덩어리를 기본 단위로 사용하는데 이를 ‘바이트’라고 부른다.
| 이름 | 비트 개수 |
|---|---|
| nibble | 4 |
| byte | 8 |
| half word | 16 |
| word | 32 |
| double word | 64 |
word는 컴퓨터가 빠르게 처리할 수 있는 가장 큰 덩어리를 뜻한다.
큰 수를 표현하는 표준 용어로 미터법에서는 킬로(1천), 메가(100만), 기가(10억), 테라(1조)를 뜻한다. 컴퓨터에서는 약간 바꿔서 밑이 10이 아닌 2인 값을 표현하여 킬로비트, 킬로바이트에서는 1000이 아닌 1024 즉 2¹⁰을 뜻한다. 하지만 때때로 밑이 10인 용어를 뜻할 때도 있어 어떤 밑으로 해석할지 문맥을 봐야하는데 IEC 표준 접두사가 만들어지면서 밑이 2인 표현법은 키비(KiB), 메비(MiB), 기비(GiB), 테비(TiB)
텍스트 표현
1) 아스키 코드
텍스트를 표현하는 방법의 경우 정보 교환을 위한 미국 표준 코드 ASCII를 사용한다 이는 키보드에 있는 모든 기호에 대해 7비트 수 값을 할당했다.
https://stepbystep1.tistory.com/10
아스키 코드 표에서 몇 가지 재밌는 코드도 눈에 띈다. 장치를 제어하기 위해 쓰이는 제어 문자라고 불리는 코드로 NUL(null), ACK(수신확인), NAK(반수신확인) 등등이 있다.
2) 다른 표준의 진화
아스키코드는 영어를 표현하는데 필요한 모든 문자를 포함하고 있어 상당 기간 표준 역할을 했으나 컴퓨터가 널리 쓰이게 됨에 따라 그 밖의 언어를 지원해야할 필요가 점차 늘어났다. 따라서 각 나라에서 자신들의 표준을 만들었으나 비트 가격이 떨어짐에 따라 유니코드라는 새로운 표준이 만들어졌고, 문자에 16비트 코드를 부여했으나 현재는 21비트까지 확장되었다.
3) 유니코드 변환 형식 8비트
유니코드는 문자 코드에 따라 각기 다른 인코딩을 사용한다. 유니코드 변환 형식 8비트(UTF-8)은 현재 가장 널리 쓰이고 있고, 이는 모든 아스키 문자를 8비트로 표현하기 때문에 아스키 데이터를 인코딩할 때 추가적인 공간이 필요하지 않다. 또 아스키가 아닌 문자의 경우 아스키를 받아서 처리하는 프로그램이 깨지지 않는 방법으로 문자를 인코딩 한다.
UTF-8은 문자를 8비트 덩어리(옥텟)의 시퀀스로 인코딩한다. UTF-8로 인코딩할 때 7비트 안에 문자의 코드가 범위안에 들어간다면 UTF-8 인코딩에서 덩어리를 하나만 사용하고 MSB는 0으로 설정한다.
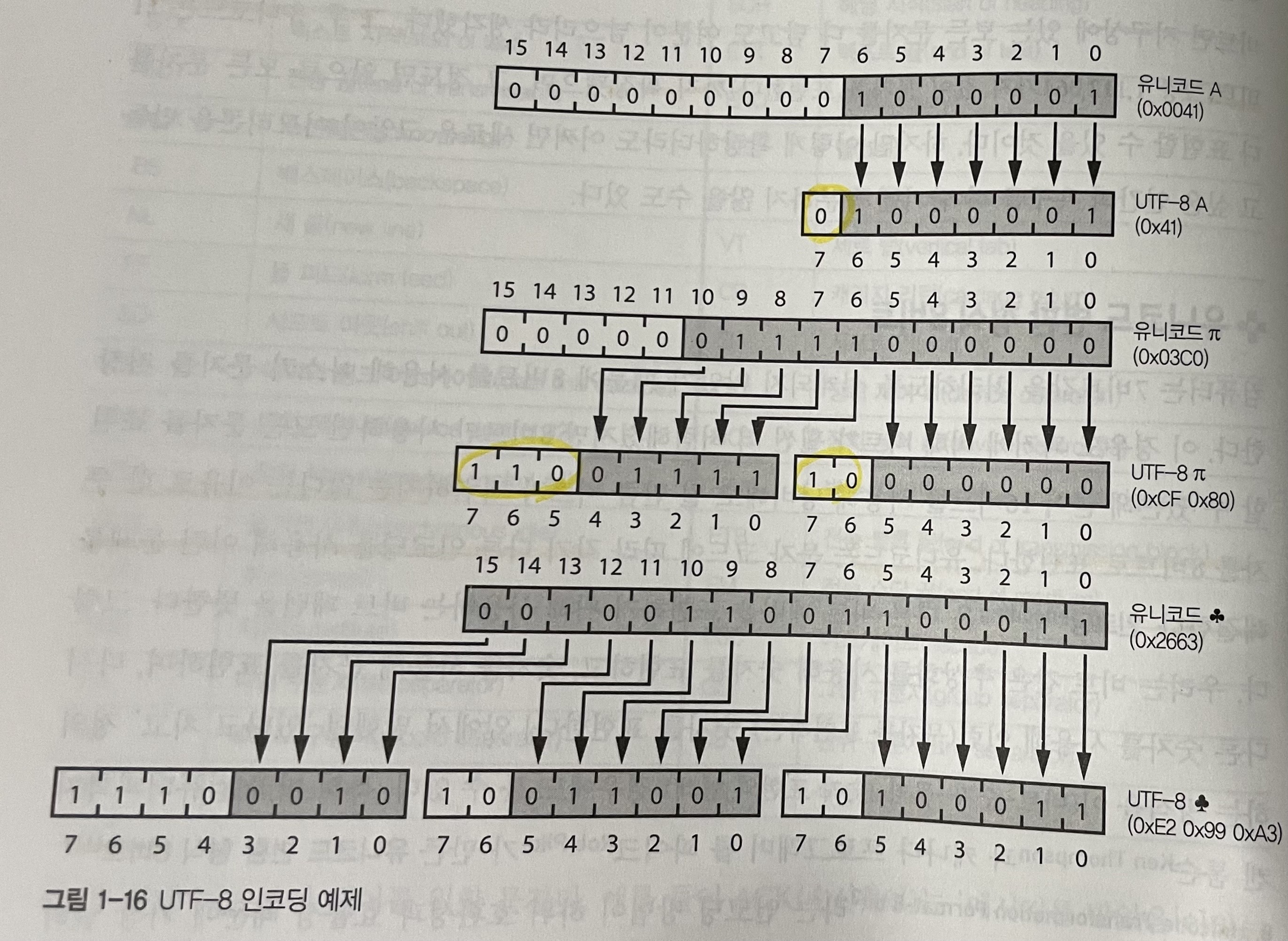
문자를 사용한 수 표현
사람들은 컴퓨터 사이에 송수신시에 2진 데이터를 보내고 싶었다. 하지만 2진 데이터를 직접 보내는 것은 생각처럼 단순하지 않았다. 아스키 코드 중 상당수가 제어 문자로 예약되어 있어고, 이런 제어 문자는 시스템에 따라 처리하는 방식이 달랐기 때문이다.
1) 출력 가능하게 변경한 인코딩
출력 가능하게 변경한 인코딩(QP인코딩)은 8비트 데이터를 7비트 데이터만 지원하는 통신 경로를 통해 송수신하기 위한 인코딩 방법이다. QP인코딩은 전자우편 첨부를 처리하기 위해 만들어졌다. 이 인코딩을 사용하면 = 다음에 바이트의 각 니블을 표현하는 16진 숫자 2개를 추가해 8비트 값을 표현한다.
QP 인코딩은 몇 가지 규칙을 가지고 있다. 줄의 맨 끝에 탭과 공백 문자가 온다면 이를 각각 =90, =20으로 표현해야만 한다. 또 인코딩된 데이터는 한 줄이 76자를 넘을 수 없다. 그리고 줄의 맨 뒤가 =으로 끝나면 가짜 줄바꿈을 뜻하며 수신쪽에서 QP로 인코딩된 데이터를 디코딩할 때는 이 =을 제거하고 해석한다.
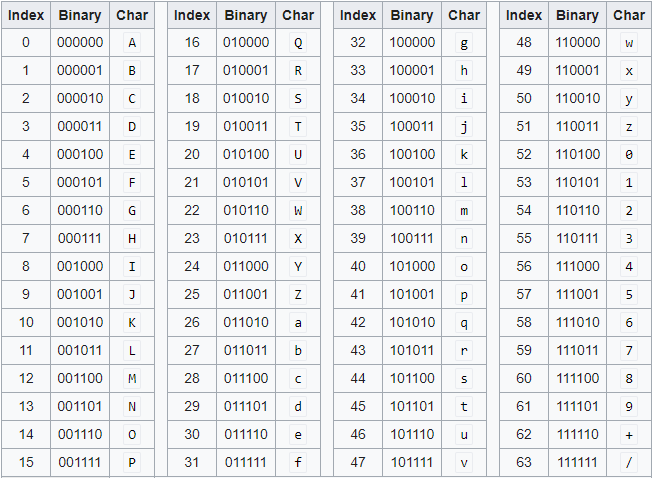
2) 베이스64 인코딩
QP인코딩이 잘 동작하기는 하나 1바이트를 표현하기 위해 3바이트를 사용하기 때문에 아주 비효율적이다. 베이스64 인코딩이 더 효율적인데 이는 3바이트 데이터를 4문자로 표현한다. 3바이트 데이터의 24비트를 네 가지 6비트 덩어리로 나누고 각 덩어리의 6비트 값에 출력 가능한 문자를 할당해 표현한다.
3) URL 인코딩
웹 페이지 URL에서 %26, %2F 같은 문자 시퀀스를 사용한다. 이런 값이 있는 이유는 URL이라는 문맥에서 몇몇 문자가 특별한 의미를 지니기 때문이다. URL 인코딩은 퍼센트 인코딩이라고도 부르는데, %뒤에 어떤 문자의 16진 표현을 덧붙이는 방식으로 문자를 인코딩한다.
예)/는 URL에서 특별한 의미를 지닌다. 그래서 /가 표현하는 특별한 의미를 뜻하고 싶지 않은 경우 /를 %2F라는 문자열로 대신한다.
색을 표현하는 방법
컴퓨터 그래픽스는 전자 모눈종이에 해당하는 것에 색을 표현하는 점을 찍어서 그림을 만드는 과정이다. 이때 모눈의 각 격자에 짝는 점을 ‘그림 원소’라고 부르고 줄여서 ‘픽셀’이라고 부른다. 컴퓨터 모니터는 빨간색, 녹색, 파란색 광선을 섞어서 색을 만들어 내고, 이런 식으로 빛을 혼합해 색을 표현하는 방식을 ‘가산’색 시스템이라고 부른다. 현대 컴퓨터들은 색을 표현하는 데 24비트를 사용해 1천만에 가장 가까운 2의 제곱수에 해당하는 색을 표현할 수 있다. 24비트에 해당하는 이름이 없는데 이는 컴퓨터들이 24비트 단위로 계산을 수행하도록 설계되어 있지 않기 때문인다. 따라서 24비트에 가까운 표준 크기인 32비트(word)에 색을 넣어서 처리하곤 한다.
또 색을 표현할 때 낭비되는 비트들이 많다.그래서 이런 남는 비트를 활용하기 위해 투명도를 표현하는데 사용하게 된다.
1) 투명도 추가
초기 애니메이션에서는 각 프레임을 손으로 그렸으나 각 프레임의 배경을 정확히 재생산할 방법이 없어 수없이 많은 시각적인 흔들림이 존재했다. 이후 셀 애니메이션을 발명해 움직이는 캐릭터를 투명 셀룰로이드 필름위에 그려서 정적인 배경이미지 위에서 움직일 수 있게 하였다. 이처럼 투명도가 있다면 여러 이미지를 하나로 합성하거나 결합할 수 있다.
투명도와 합성을 구현하는 새로운 방법이 발명됐고 이 방법은 표준이 되었다. 각 픽셀에 알파라는 투명도 값을 추가했는데 이는 부동소수점을 사용하지 않았기 때문에 1~255까지의 값을 알파 값으로 사용했고, 사용하지 않는 비트들을 활용했다.
2) 색 인코딩
웹 페이지에서는 주로 사람이 읽을 수 있는 UTF-8 문자의 시퀀스로 이뤄지는 텍스트를 표현하기 때문에 텍스트를 사용해서 색을 표현할 방법이 필요하다. 웹에서는 색을 16진 트리플렛으로 표현한다. 이는 # 뒤에 여섯자리의 16진 숫자를 추가해 #rrggbb처럼 표현하는 방식이다.