
기본 데이터 타입
프로그래밍 언어에는 다양한 기본 데이터 타입을 제공한다. 이런 타입에는 크기(size)와 해석이라는 두 가지 측면이 존재한다.
1964년 포인터를 발명했다. 포인터는 단지 컴퓨터 아키텍처에 따라 결정되는 크기의 부호가 없는 정수에 불과하며 정숫값이 아니라 메모리 주소로 해석된다. 포인터를 통하여 원하는 값이 있는 위치를 알 수 있다. 포인터는 C언어가 인기를 끌면서 유명세를 탔고 일부 언어는 잘못된 포인터 사용으로 인한 오류를 막기 위해 참조라는 더 추상적인 개념을 구현하기도 한다.
배열
프로그래밍 언어는 배열을 지원한다. 배열은 마치 아파트와 같다. 아파트 한 동에는 주소가 있고, 동 안의 각 집에는 번호가 있다. 프로그래머는 이 호수를 인덱스라고 부르고 각각의 집을 원소(element)라고 부른다. 일반적인 컴퓨터 개발 규정에는 배열 원소의 타입이 모두 같아야 한다고 정해져 있다.
배열에서 각 원소는 0번째 원소의 주소인 기저 주소로부터 얼마나 멀리 떨어져 있는지를 나타내는 오프셋으로 지정할 수 있다. 프로그래밍 언어는 다차원 배열을 지원하기도 한다. 다차원 배열이 메모리에 어떻게 저장되는지 잘 알아야 한다.
예) 4 X 3 2차원 아파트 건물 집집마다 전단지를 돌린다고 할때 1)[0,0], [0,1], [0,2], [1,0], [1,1], [1,2]….순으로 방문 2)[0,0], [1,0], [2,0], [0,1], [1,1], [2,1]…순으로 방문
두 번째 방식이 첫 번째 방식보다 지역성이 좋고 힘도 덜 든다. 열 인덱스가 1 바뀌면 [0,0] -> [0,1] 인접한 메모리 위치에 있는 원소로 이동하지만 행 인덱스가 1 바뀌면 [0,0] -> [1,0] 인접한 행으로 이동해야 하기 때문에 연속적인 메모리 공간상으로는 배열의 열 개수만큼 떨어져있는 메모리 위치에 있는 원소로 이동해야 한다. 따라서 주소 공간상에서는 열 인덱스가 바뀔 때보다 행 인덱스가 바뀔 때 더 많은 이동이 일어난다.
비트맵
기본 데이터 타입을 사용해 배열을 사용하는 경우 원하는 데이터를 표시하기에는 기본 데이터가 너무 클 때도 있다. 그럴때 비트의 배열인 비트맵을 사용할 수 있다. 비트맵에 대해 수행할 수 있는 기본 연산은 1)비트 설정하기(set), 2)비트 지우기(clear), 3)비트가 1인지 검사하기, 4)비트가 0인지 검사하기 네 가지가 있다.
정수 나눗셈을 통해 특정 비트가 들어 있는 바이트를 찾을 수 있다. 필요한 연산은 8로 나누는 것 뿐이다. 다음 단계로 비트 위치에 대한 마스크를 만들어야 한다. 마스크는 들여다볼 수 있는 구멍이 있는 비트 패턴을 말한다. 배열 인덱스와 비트 마스크를 사용하면 비트맵 기본연산을 쉽게 수행할 수 있다. 또 자원이 사용 가능하거나 사용 중인지 여부를 나타낼ㄷ 때도 비트 맵을 유용하게 사용할 수 있다.
문자열
여러 문자로 이뤄진 시퀀스를 문자열이라고 한다. 배열과 마찬가지로 문자열을 연산할 때도 그 길이를 알아야 한다. 한 가지 접근 방법은 문자열 안에 길이를 저장하는 것이다. 하지만 이 방법은 잘 작동하지만 문자열 길이가 255자로 제한된다는 단점을 가지고 있다.
C언어에서는 다른 접근 방법을 사용한다. 문자열을 위한 전용 데이터 타입을 제공하지 않고 대신 1차원 바이트 배열을 사용한다.(char) C 문자열은 길이를 저장하지 않고 대신 무자 배열에 들어있는 문자열 데이터의 끝에 바이트를 하나 추가하고 문자열의 끝을 표시하는 문자로 NUL(문자열 터미네이터)을 넣는다.
이런 문자열 터미네이터를 사용하는 방식에는 장단점이 있는데 중요한 장점으로 저장이 쉽다는 점이 있고, 문자열의 끝까지 각 문자를 출력하는 일을 할 때 부가 비용이 들지 않는다는 점이 있다. 단점으로는 문자열의 길이를 알아내려면 문자열 터미네이터를 발견할 때까지 문자열을 스캔하면서 문자 수를 세야한다. 또 문자열 중간에 NUL 문자를 넣고 싶을때는 이 방법을 사용할 수 없다.
복합 데이터 타입
현재 대부분의 언어는 우리가 원하는대로 데이터 타입, 즉 suite를 만들 수 있는 방법을 제공한다. 이를 구조체라고 한다. 그리고 구조체 스위트 안에 있는 여러 방을 구조체의 멤버라고 한다.
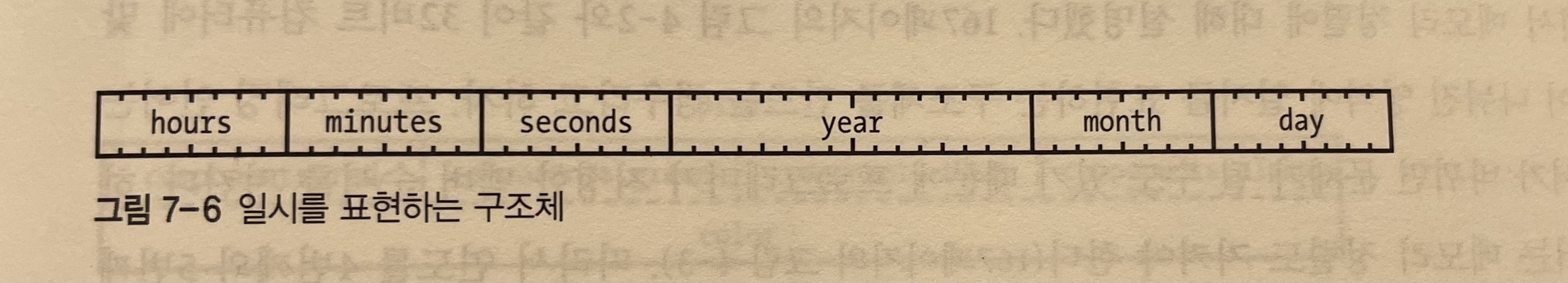
스위트 같은 데이터 구조 이외에 움직일 수 있는 파티션으로 구분한 사무실 같은 데이터 구조를 사용할 수도 있다. 이런 데이터 구조를 C에서는 공용체라고 부른다. 공용체를 사용하면 같은 메모리 공간이나 내용을 여러 가지 관점으로 바라볼 수 있다.
구조체와 공용체의 차이점은 구조체 안의 모든 멤버는 각기 다른 메모리를 차지하지만 공용체의 멤버들은 메모리를 공유할 수 있다는 데 있다.
단일 연결 리스트
데이터 양이 정해져 있지 않은 경우 배열이 적합하지 않다. 배열을 충분히 크게 만들지 않으면 데이터가 늘어난 경우 새로 더 큰 배열을 만들고 기존 배열의 내용을 새 배멸로 복사해야한다. 반대로 배열의 크기를 크게 잡아놓으면 메모리를 너무 낭비하게 된다.
연결 리스트는 목록에 들어갈 원소 개수를 모르는 경우 배열보다 더 잘 작동한다.
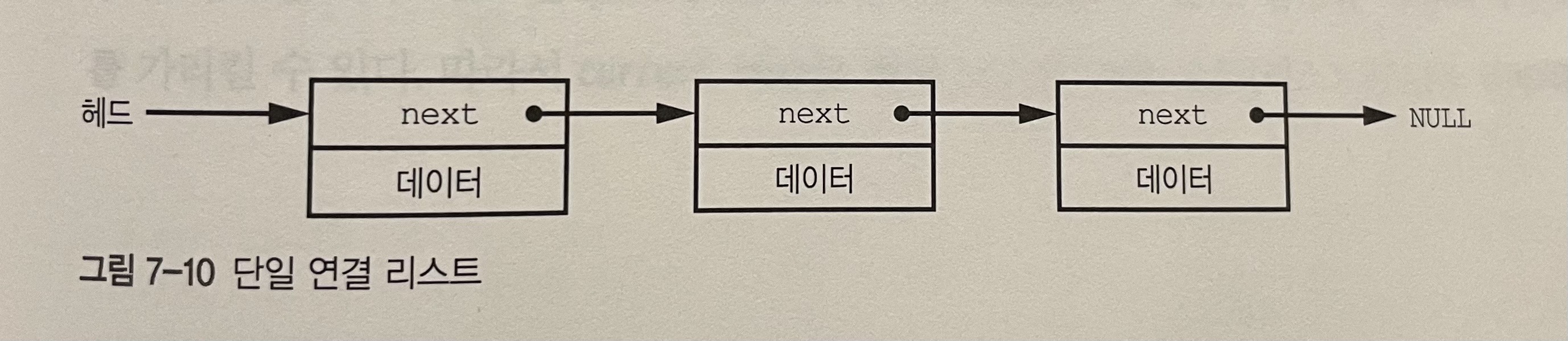
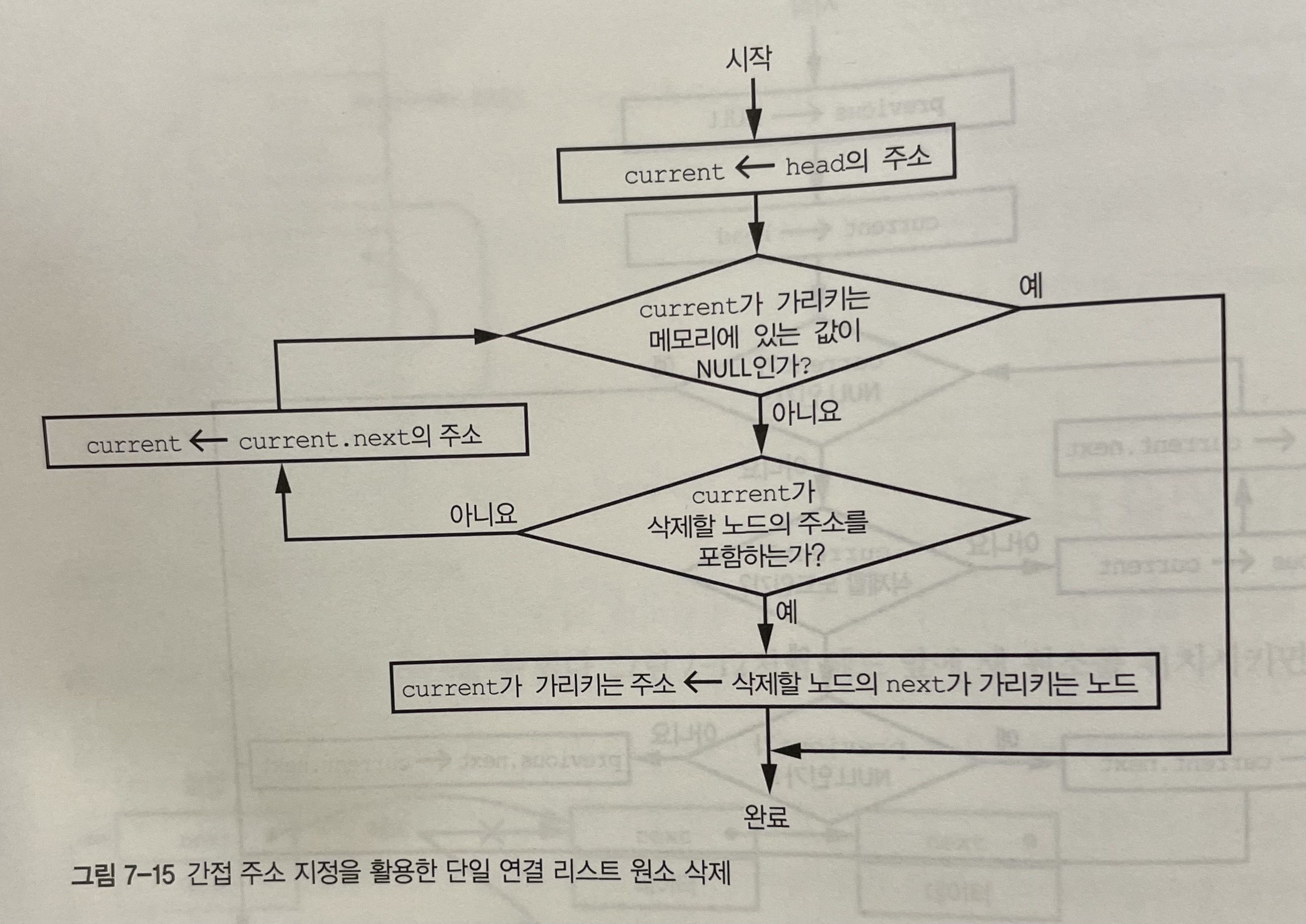
next는 리스트의 다음 원소 주소를 저장하는 포인터고, 리스트에서 맨 앞은 헤드, 마지막은 테일이다. 배열과의 차이점은 배열은 메모리에 연속적으로 위치하지만, 리스트 원소는 메모리에서 아무 위치에나 있을 수 있다는 점이 있다. 따라서 리스트에는 원소를 쉽게 추가할 수 있다. 삭제는 조금 복잡한데 삭제할 원소의 바로 앞 원소의 next 포인터가 삭제할 원소의 next 포인터가 가리키는 원소를 가리키게 해야하기 때문이다.
동적 메모리 할당
별도의 메모리 관리 유닛(MMU)가 없는 컴퓨터라면 Heap 영역이 프로그램에 사용할 수 있는 모든 데이터 메모리다. 배열 등의 변수가 사용하는 메모리는 정적이고 이런 변수에 할당된 주소는 바뀌지 않는다. 리스트 노드와 같은 존재는 동적이다. 이들은 필요에 따라 생기기도 하고 사라지기도 한다. 이런 동적인 대상에 사용할 메모리를 힙에서 얻는다.
프로그램은 힙을 관리할 수 있어야한다. 사용중인 메모리를 알아야 하고, 사용가능한 메모리도 알아야 한다. 이런 목적에 사용하는 라이브러리 함수가 있어 직접 구현할 필요가 없다. 대표적으로 C에는 malloc과 free 함수가 있다.
경험이 적은 프로그래머는 할당하지 않은 메모리를 해제하는 실수를 자주 저지른다. 또 반대로 이미 해제된 메모리를 계속 사용하는 실수도 종종 저지르곤 한다. 할당 받은 메모리 경계 밖에 데이터를 쓰면 size와 next 필드를 오염시킬 수 있다.
더 효율적인 메모리 할당
텍스트 문자열이 들어있는 연결리스트는 노드에 사용할 메모리는 물론 문자열에 사용할 메모리도 할당해야 한다. 노드와 문자열을 동시에 할당하면 부가비용을 줄일 수 있다. 노드를 할당한 후 문자열을 할당하는 대신에 노드와 문자열의 크기를 합하고, 메모리 경계를 지키기 위해 필요한 패딩을 추가한 크기의 공간을 할당할 수 있다.
가비지 컬렉션
동적 메모리를 명시적으로 관리하면서 포인터를 잘못 쓰면 두 가지 문제가 생긴다. 1)포인터는 단지 메모리 주소를 나타내는 숫자이지만 모든 숫자가 올바른 메모리 주소는 아니다. 2)포인터를 사용해 존재하지 않은 메모리에 접근하거나 프로세서의 메모리 경계에 맞지 않는 주소에 접근하면 예외가 발생하면서 프로그램이 중단된다.
자바나 자바스크립트 언어에는 포인터가 없고 직접 malloc, free를 하지 않고도 동적 메모리 할당을 지원한다. 이런 언어들은 가비지 컬렉션을 구현한다.
자바 같은 언어는 포인터 대신 참조를 사용하고 참조는 포인터를 추상화해서 거의 비슷한 기능을 제공하지만 실제 메모리 주소를 노출하지 않는다.
가비지 컬럭션은 언어의 런타임 환경이 변수 사용을 추적해서 더이상 사용하지 않는 메모리를 자동으로 해제해준다. 한 가지 문제점으로는 프로그래머가 가비지 컬렉션 시스템을 제어할 수 없다는 점이다. 이로인해 프로그램이 중요한 일을 하는 도중 가비지 컬렉션 시스템이 작동돼서 문제가 생기는 경우도 있다.
이중 연결리스트
단일 연결리스트는 delete 함수에서는 포인터를 제대로 변경하기 위해 삭제하려는 원소의 바로 앞 원소를 찾아야 한다. 이로 인해 단일 연결리스트의 delete 연산은 상당히 느리다.
이중 연결리스트는 노드에 다음 원소에 대한 포인터뿐만 아니라 이전 원소에 대한 포인터도 들어있는 리스트이다. 노드당 부가 비용은 2배가 되지만 delete시 노드를 앞에서부터 방문할 필요가 없어진다.
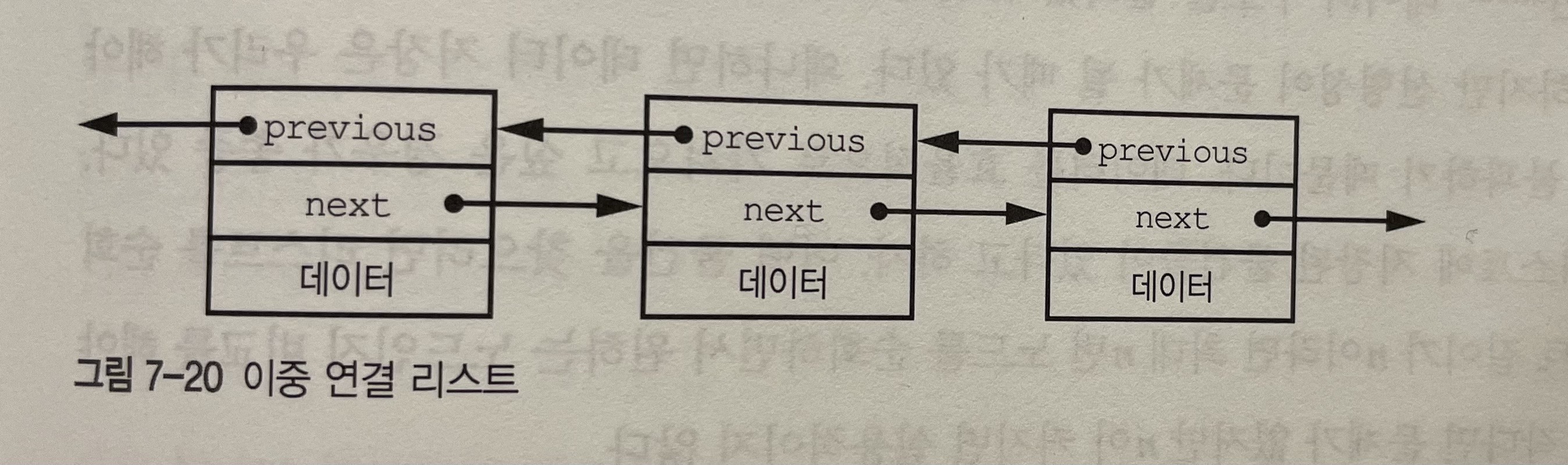
이중 연결 리스트의 장점은 리스트 전체를 방문하지 않아도 원하는 위치에 노드를 추가하거나 삭제할 수 있다는 점이다.
계층적인 데이터 구조
지금까지는 선형적인 데이터 구조를 살펴봤다. 선형성이 문제가 되는 경우가 있는데 데이터를 효율적으로 가져오고 싶은 경우 연결리스트 같은 경우 리스트를 순회해야만 한다. 리스트의 길이가 n이라면 최대 n번 노드를 순회하면서 원하는 노드인지 비교를 해야한다.
간단한 계층적 데이터 구조는 2진 트리다. 2진이라는 말은 노드가 최대 2개의 다른 노드와 연결될 수 있기 때문에 붙은 말이다. 트리의 루트는 연결 리스트의 헤드에 해당한다.
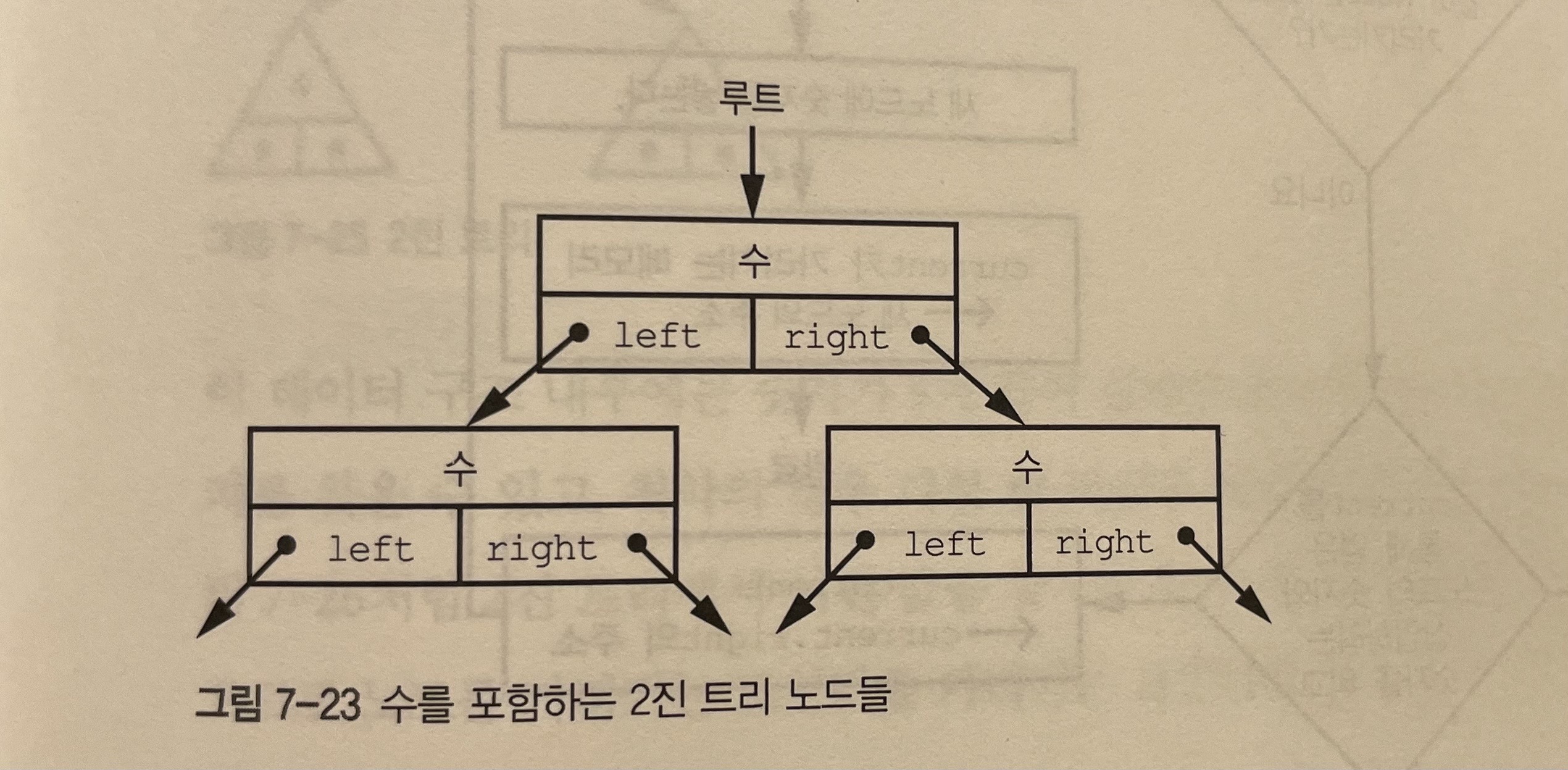
2진 트리에서 어떤 대상을 검색하는 연산은 트리 깊이에 의해 정의되는 함수다. 만약 트리가 n계층만큼 아래로 내려간다면 검색시 n번만 원소를 비교하면 된다.
대용량 저장장치
디스크의 기본 단위는 블록이고 연속적인 블록을 클러스터라고 한다. 클러스터는 한 트랙 안에 있는 연속적인 섹터로 이뤄지므로 데이터를 한 클러스터에만 저장할 수 있으면 좋을 것이다. 일반적인 해법으로 한 클러스터에 데이터를 저장하는 방식이 그리 바람직하지 않고 한 클러스터에 들어가기에는 너무 큰 데이터도 있기 마련이다. 대신 데이터는 사용가능한 섹터가 있다면 위치와 관계없이 저장된다. 어떤 데이터를 저장하기 위한 저장소 블록을 찾는 대신 어떤 데이터를 저장하기에 충분한 크기가 되도록 고정된 크기의 블록을 여럿 확보해서 데이터를 블록에 나눠 담아야 한다.
파일 이름을 디스크에 저장할 방법과 파일 이름과 파일의 데이터가 저장된 디스크 블록을 연결해줄 방법이 필요한다. 블록 중 일부를 아이노드로 따로 지정하는 것이다. 아이노드는 디스크 블록에 대한 인덱스와 노드를 합친 단어다. 아이노드에는 여러가지 정보가 들어간다. 그리고 파일의 데이터가 들어 있는 블록에 대한 인덱스도 포함된다.
아이노드에는 보통 직접 블록 포인터가 12개 있다. 이를 통해 최대 49,152 바이트까지 데이터를 보관할 수 있다. 파일이 더 커지면 간접 블록을 사용하기 시작한다. 만약 이보다 더 큰 파일을 저장해야 한다면 2중 간접 블록을 통해 4GiB까지 3중 간접 블록을 통해 4PiB까지 지원할 수 있다.
아이노드 정보 중에는 블록에 데이터가 있는지 디렉터리 정보가 있는지를 표시하는 것도 있다. 디렉터리는 다른 디렉터리를 참조할 수 있고 이로인해 트리 구조의 계층적 파일 시스템이 생겨났다.
데이터베이스
데이터베이스는 정해진 방식으로 조직화된 데이터 모음이다. 데이터베이스 관리시스템은 데이터베이스에 정보를 저장하고 읽어올 수 있게 해주는 프로그램이다. 데이터베이스는 B 트리 데이터 구조를 활용한 시스템이다. B 트리는 균형 트리이지만 2진 트리는 아니다.
인덱스
인덱스의 경우 유지보수를 해야 한다는 트레이드 오프가 있다. 데이터가 바뀔 때마다 모든 인덱스를 갱신해야 한다.
데이터 이동
305~308p
벡터를 사용한 I/O
시스템 성능에 있어 데이터를 효율적으로 복사하는 것이 중요하다. 하지만 복사를 아예 피할 수 있으면 성능을 더 높일 수 있다.
오디오 데이터를 오디오 장치로 보내고자 할 때 크기와 데이터에 대한 포인터로 이뤄진 벡터를 운영체제에 넘기면 된다. 운영체제는 이 벡터를 저장된 데이터를 사용해 순서대로 오디오 프레임을 조합한다. 데이터를 쓰는 행위를 ‘수집’, 데이터를 읽는 행위를 ‘분산’이라고 한다.
객체지향의 함정
객체에는 함수에 해당하는 메서드와 데이터에 해당하는 프로퍼티가 있다. 어떤 객체에 필요한 모든 데이터와 함수는 한 데이터 구조 안에 모여 있다.
객체지향 사상가들은 객체가 모든 문제를 해결할 수 있는 해답이라고 생각한다. 하지만 객체와 관련된 부가 비용이 어느정도 존재하고, 객체는 전역적으로 알려진 함수대신 자신이 사용할 메서드에 대한 포인터를 가지고 다녀야 한다.
정렬
데이터를 정렬해야 하는 이유는 많다. 사람을 더 찾기 쉽게 이름을 가나다 순으로 정렬한 목록을 원하거나 정렬된 형태로 데이터를 저장하고 싶은 경우도 많다. 그렇게 되면 메모리 접근 횟수를 줄여 검색을 빨리 끝낼 수 있다.
해시
앞선 검색 메서드는 모두 데이터 구조를 순회하면서 비교를 여러번 수행해야 했다. 경우에 따라 성능이 더 좋은 접근 방법으로 해싱이 있다. 일반적으로 검색에 사용할 키에 대해 균일하게 벽에 흩뿌려주는 해시 함수를 적용하는 것이다. 해시 함수의 결과값을 사용해 키에 대응하는 데이터를 메모리에 저장할 수 있다. 또 해시 함수의 결과를 배열 인덱스로 활용하는 방법으로 해시 테이블이 있다.
좋은 해시함수는 계산하기 쉬워야하고, 키를 골고루 버킷에 뿌려줘야 한다.
효율성과 성능
성능과 효율이 분리된 상황을 응용하는 방법으로 데이터베이스 샤딩이 있다. 샤딩은 다른말로 수평 파티셔닝이라고도 부른다. 이는 각각 다른 기계에서 실행되는 여러 샤드로 나누는 방식을 말한다.
또 샤딩의 변종으로 맵 리듀스가 있다. 맵 리듀스는 근본적으로 컨트롤러가 중간 결과를 모으는 방법을 코드로 직접 작성할 수 있다.