OOP
현실세계의 사물, 개념을 객체로 표현하고 객체들간의 유기적인 상호작용을 통해 프로그래밍 하는 방법이다. 사람의 사고와 가장 비슷하게 프로그래밍을 하기 위해 생성된 기법이고, 코드의 재사용성과 중복제거, 유지보수에 용이하다.
[특징]
- 추상화 : 불필요한 세부사항을 제거하고, 객체의 공통된 속성들을 하나의 클래스로 정의하여 단순하게 만드는 것
- 캡슐화 : 외부에 노출할 필요가 없는 정보들은 은닉하는 것으로 데이터에 직접적으로 접근하는 것을 막고 오로지 메소드를 통해서만 접근할 수 있다.
- 상속 : 부모 클래스가 자손 클래스에게 속성을 물려줌으로써 코드를 재사용하는 것이다.
- 다형성 : 같은 형태이지만 다른 기능을 하는 것으로 오버로딩, 오버라이딩이 있다.
[장점]
- 강한 응집력, 약한 결합력을 가짐
- 코드가 간결해지고, 재사용성, 확장성이 높다.
[단점]
- 각 모듈의 높은 독립성을 권장하여 여러 클래스를 상속해 중복코드를 최소화하고 유지보수성을 높인다 그렇기 때문에 실행 속도가 느리다.
- 객체가 많으면 용량이 커질 수 있다.
- 설계에 시간과 노력이 필요하다.
OOP 설계의 원칙
[SOLID]
Single Responsibility Principle (단일 책임 원칙) : 객체는 단 하나의 책임만 가져야 한다.Open Closed Principle (개방-폐쇄 원칙) : 소프트웨어의 요소는 확장에는 열려 있고(기능의 추가), 변경에는 닫혀 있어야 한다.(기존 코드를 변경하지 않는)Liskove Substitution Principle (리스코프 치환 원칙) : 자식 클래스는 최소한 자신의 부모 클래스에서 가능한 행위는 수행할 수 있어야 한다. -> 부모 클래스와 자식 클래스 사이의 행위에는 일관성이 있어야 한다는 원칙Interface Segregation Principle (인터페이스 분리 원칙) : 클래스는 자신이 사용하지 않는 인터페이스는 구현하지 말아야 한다. -> 자신이 사용하지 않는 기능에는 영향을 받지 말아야 한다.Dependency Inversion Principle (의존 역전 원칙) : 의존 관계를 맺을 때 변화하기 쉬운것(구체적인 것) 보다는 변화하기 어려운 것(추상적인 것)에 의존해야 한다. -> 의존 관계를 맺을 때 구체적인 클래스보다는 인터페이스나 추상 클래스와 관계를 맺는 다는 것을 의미
Overriding / Overloading
오버라이딩 : 부모 클래스 상속시 상속받은 메소드를 자식 클래스에서 재정의 하는 것으로 부모 클래스의 메소드 선언부(이름, 매개변수, 반환타입)와 일치해야 한다.
오버로딩 : 하나의 클래스안에 동일한 이름의 메소드를 여러개 정의하는 것으로 메소드의 이름이 같아야 하고, 매개변수의 갯수 또는 타입이 달라야 한다. (반환타입은 상관 없음)
Static 키워드
어떠한 값이 메모리에 한 번 할당되어 프로그램이 종료될 때까지 메모리에 값이 유지되는 것을 나타낸다. static 키워드를 통해 생성된 정적 멤버는 Heap 영역이 아닌 static 영역에 할당되고 static 영역에 할당된 메모리는 모든 객체가 공유하는 메모리라는 장점을 지니지만 가비지 컬렉터가 관리하는 영역 밖이므로 자주 사용하게 되면 시스템 성능에 악영향을 주게 된다.
*메서드에 사용시 객체의 생성 없이 호출 가능하다.
직렬화
직렬화는 자바에서 입출력시 스트림을 통해 데이터가 이동하는데 이때 바이트 배열로 변환하여 보내주어야 한다. 즉 객체를 바이트 배열로 변환하는 것을 나타내는 것이다. ↔ 역직렬화는 직렬화와 반대로 바이트로 변환된 데이터를 다시 객체로 변환하는 것이다.
String / StringBuffer / StringBuilder
String : 한 번 생성되어 할당된 메모리 공간이 변하지 않는다. 그래서 새로운 값이 할당된 경우 메모리 공간을 새롭게 차지하여 많은 연산이 발생시 성능이 떨어진다.
StringBuffer : 문자열 연산등으로 기존 객체의 공간이 부족한 경우 버퍼 크기를 늘려 유연하게 동작한다. 멀티 쓰레드 환경에서 동기화를 지원함
StringBuilder : StringBuffer와 같으나 멀티 쓰레드 환경에서 동기화를 지원하지 않는다.
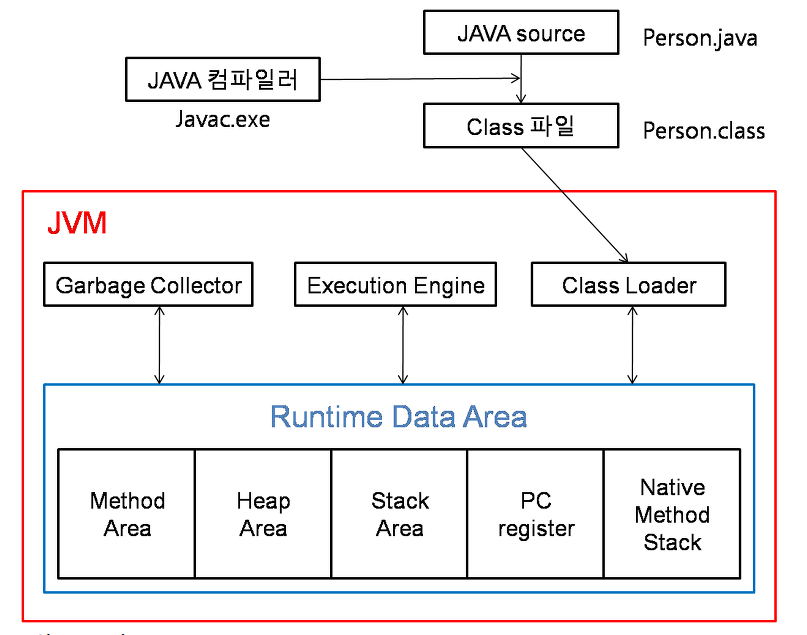
JVM
JVM은 자바 가상 머신의 약자로 자바 컴파일러가 자바 파일을 컴파일 하면 자바 바이트 코드로 변환시켜 준다. 이때 바이트 코드는 기계어가 아니기 때문에 OS가 이해할 수 있도록 해석해주는 작업을 해주는 것이 JVM 이다. 자바와 OS 사이에 중개자 역할을 수행하여 자바가 OS에 구애받지 않고 프로그램을 실행할 수 있도록 도와준다. 또 가비지 컬렉터를 사용한 메모리 관리도 자동으로 수행된다.
[구성]
- Class Loader : JVM 내로 클래스 파일을 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈이다. 런타임 시에 동적으로 클래스를 로드한다.
- execution Engine(실행 엔진) : 클래스 로더를 통해 JVM 메모리 내에 배치된 바이트 코드들을 명령어 단위로 읽어서 기계가 실행할 수 있는 형태로 변경한다.
- Garbage Collector : heap 메모리 영역에 생성된 객체 중 참조되지 않은 객체들을 탐색 후 제거하는 역할을 한다.
- Runtime Data Area : 자바 애플리케이션을 실행할 때 사용되는 데이터를 적재하는 메모리 영역이다.
- Method Area - 모든 쓰레드가 공유하는 메모리 영역, 클래스, 인터페이스, 필드, static 변수 등 바이트 코드를 보관
- Heap Area - 모든 쓰레드가 공유, new 키워드로 생성된 객체, 배열이 생성되는 영역이다. 가비지 컬렉터가 관리하는 영역
- Stack Area - 지역변수, 파라미터, 리턴 값, 연산에 사용되는 임시 값 등이 생성되는 영역이다. 메서드 호출시 개별적으로 스택이 생성됨
- PC register - 쓰레드가 생성될 때마다 생성되는 영역으로 현재 쓰레드가 실행되는 부분의 주소와 명령을 저장하고 있는 영역이다.
- Native Method Stack - 자바 외 언어로 작성된 네이티브 코드를 위한 메모리 영역
class / 객체 / 인스턴스의 차이
class : 객체를 만들어 내기 위한 설계도, 틀, 연관되어 있는 변수와 메서드의 집합이다.
객체 : ‘클래스의 인스턴스’로 불리며 소프트웨어 세계에 구현할 대상 클래스에 선언된 실체이다.
인스턴스 : 객체가 실제로 구현된 ‘구체적인 실체’를 의미한다.
클래스는 설계도, 객체는 설계도로 구현한 모든 대상을 의미한다. 클래스 타입으로 선언되었을 때 객체라 부르고, 그 객체가 메모리에 할당되어 실제 사용될 때 인스턴스라고 부른다.
생성자
생성자는 인스턴스가 생성될 때 호출되는 ‘인스턴스 초기화 메서드’ 이다. 따라서 반환 값이 없고, 하나의 클래스에는 반드시 하나 이상의 생성자가 존재해야 한다. 클래스 이름과 동일하고, 인스턴스 생성시 딱 한 번 호출된다.
- 기본 생성자 : 파라미터가 하나도 없는 생성자
- 묵시적 생성자 : 컴파일시 생성자가 하나도 정의되어 있지 않은 경우 컴파일러가 자동으로 기본 생성자를 생성해서 컴파일해준다.
- 명시적 생성자 : 개발자가 직접 선언한 생성자, 명시적 생성자 작성시 기본 생성자를 자동으로 생성해주지 않음
this
this는 객체, 자기 자신을 가리킨다.
[특징]
- 객체 자신의 대한 참조값을 가진다. 즉, 자기자신을 가리킨다.
- 메소드 내에서만 사용된다.
- 객체 자신을 메소드에 전달하거나 리턴하기 위해 사용된다.
- 생성자 내에서 사용시 다른 생성자를 호출한다.
- 매개 변수와 객체 자신이 가진 변수의 이름이 동일한 경우 이를 구분하기 위해 자신의 변수에 this를 사용한다.
- static 메소드에서는 사용할 수 없다.
Interface / Abstract
인터페이스 : 함수의 구현을 강제하여 구현 객체의 같은 동작을 보장하는 목적을 가지고 있다. 다중 상속이 가능하고, 추상 클래스보다 추상화 정도가 높다. 또 일반 메서드, 일반 멤버 변수를 가질 수 없다는 특징을 갖고 있다.
추상클래스 : 추상 클래스는 추상 클래스를 상속받아서 기능을 이용하고 확장시키는 목적을 가지고 있다. 반드시 하나 이상의 추상메서드를 가지며 상속을 위한 클래스이기 때문에 객체를 생성할 수 없고, 다중 상속이 불가하다.
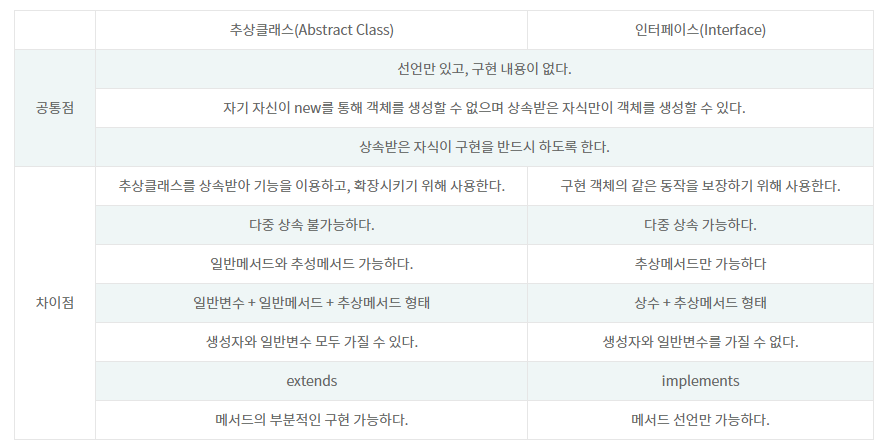
=> 어떨때 인터페이스를 사용하고 어떨때 추상클래스를 사용하는 거지..??
제네릭
제네릭은 클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법이다. 클래스나 메서드에서 사용할 내부 데이터 타입을 미리 지정하여 객체의 타입 안전성을 높일 수 있고 반환값에 대한 타입 변환, 타입 검사에 들어가는 노력을 줄일 수 있다. 런타임이 아닌 컴파일시에 타입체크를 하기 때문에 오류를 빨리 발견할 수 있다.
지역변수 / 인스턴스변수 / 클래스 변수
지역 변수 : 메서드 내에 선언되고 해당 메서드 안에서만 사용할 수 있다. 따라서 메서드가 종료되면 소멸되어 사용할 수 없다.
인스턴스 변수 : 클래스 내에 선언된 변수로 객체를 생성 할 때 만들어 진다. 독립적인 저장공간을 가지므로 생성된 객체마다 서로 다른 값을 가진다.
클래스 변수 : static 키워드로 선언된 변수로 공통된 저장공간을 공유하게 된다. JVM이 처음 실행되어 클래스가 메모리에 올라가서 종료될 때까지 유지되고, 클래스가 여러번 생성되어도 static 변수는 처음에 딱 한 번만 생성된다.
가비지 컬렉션
Heap 메모리에 동적으로 할당되었으나 시스템에서 더이상 사용하지 않는 즉 참조되지 않는 대상을 찾아 메모리에서 해제하는 JVM의 기능이다.
Call by Reference, Call by Value
함수가 호출될 때 메모리 공간안에 임시의 공간이 생성되고 함수가 종료하면 해당 공간은 사라진다. 이때 함수 호출시 전달되는 변수의 값을 사용하는 방법이 두 가지가 있다.
1)Call by Reference : ‘참조에 의한 호출’은 인자로 받은 값의 주소를 참조하여 직접 값에 영향을 준다. 복사하지 않고 직접 참조하기 때문에 빠르지만 원본 값이 바뀔 수 있다는 단점이 있다.
2)Call by Value : ‘값에 의한 호출’은 인자로 받은 값을 복사하여 함수 안에서 지역적으로 사용된다. 값을 복사하여 사용하기 때문에 안전하고 원본 값이 보존이 되지만 메모리 사용량이 늘어난다는 단점이 있다.
**Java에서는 Call by Reference가 없음 직접적으로 참조를 넘기는 것이 아닌 주소 값을 복사해서 넘기기 때문에 call by value다.
Collection (Map, Set, List)
컬렉션이란 데이터의 집합, 그룹을 의미하고 Collection 인터페이스는 List, Set, Queue로 3가지 상위 인터페이스를 분류한다. Map의 경우 Collention 인터페이스를 상속받고 있지 않지만 Collection으로 분류된다.
- Set : 순서를 유지하지 않는 데이터의 집합으로 데이터의 중복을 허용하지 않는다.
- HashSet
- TreeSet : 자동으로 정렬을 해준다.
- LinkedHashSet : 저장 순서를 유지할 수 있다.
- List : 순서가 있는 데이터의 집합으로 데이터의 중복을 허용한다.
- LinkedList : 양방향 포인터 구조로 데이터 삽입, 삭제가 빈번할 경우 유용하다.
- ArrayList : 단방향 포인터 구조로 각 데이터에 대한 인덱스 구조를 가지고 있어 조회 성능은 뛰어나나 배열의 중간에 데이터의 삽입, 삭제시 데이터의 이동이 필요하기 때문에 빈번한 경우 성능이 떨어짐
- Map : 키와 값의 쌍으로 이루어진 데이터의 집합으로 순서는 유지되지 않으며 키는 중복을 허용하지 않고, 값은 중복을 허용한다.
- HashTable : HashMap보다 느리지만 동기화 지원, null 불가
- HashMap : 중복, 순서 허용X, null 값이 올 수 있다.
- TreeMap : 정렬이 되어 있어 검색시 성능이 빠르다.
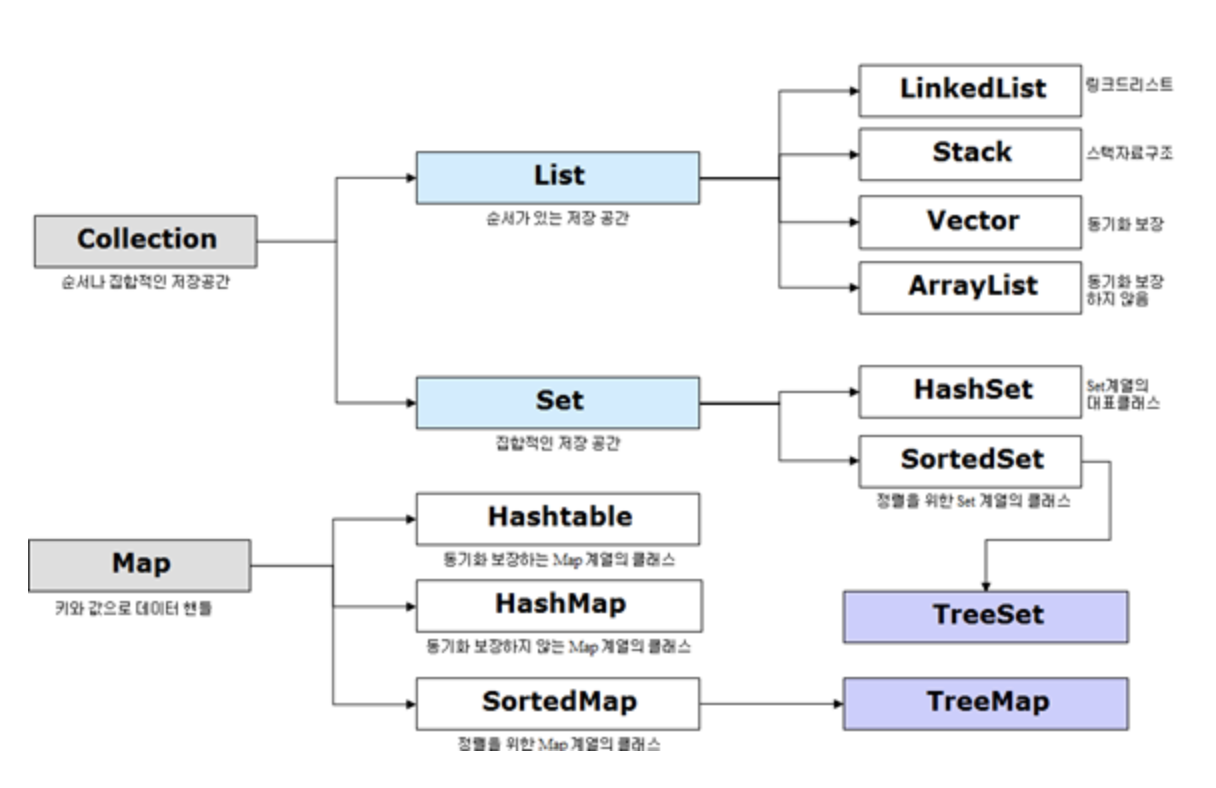
**Collections 클래스는 Collection 인터페이스를 리턴하거나 인터페이스에서 동작하는 메서드를 모아놓은 클래스이다.
Thread
스레드란 하나의 프로세스내에 독립적으로 실행되는 하나의 작업 단위이다. JVM에 의해 하나의 프로세스가 발생하고 main 메서드 안의 실행문이 하나의 스레드이다. main 이외의 다른 스레드를 만들려면 Thread 클래스를 상속하거나 Runnable 인터페이스를 구현한다.
[스레드의 6가지 상태]
- NEW - 스레드가 생성되었지만 아직 실행할 준비가 되지 않음
- RUNNABLE - 실행 대기 상태
- WAITING - 다른 스레드가 통지할 때까지 기다리는 상태
- TIMED_WAITING - 주어진 시간동안 기다리는 상태
- BLOCK - 사용하고자 하는 객체의 락이 풀릴 때까지 기다리는 상태
- TERMINATED - 실행을 마친 상태
접근 제한자
객체의 속성들을 대외적으로 공개하는 것은 좋지 않다. 따라서 객체의 멤버들에게 접근 제한을 걸 수 있는데 그 종류로는
- public : 모든 접근을 허용한다.
- protected : 같은 패키지에 있는 객체와 상속 관계의 객체들만 허용
- default : 같은 패키지에 있는 객체들만 허용
- private : 현재 객체내에서만 허용
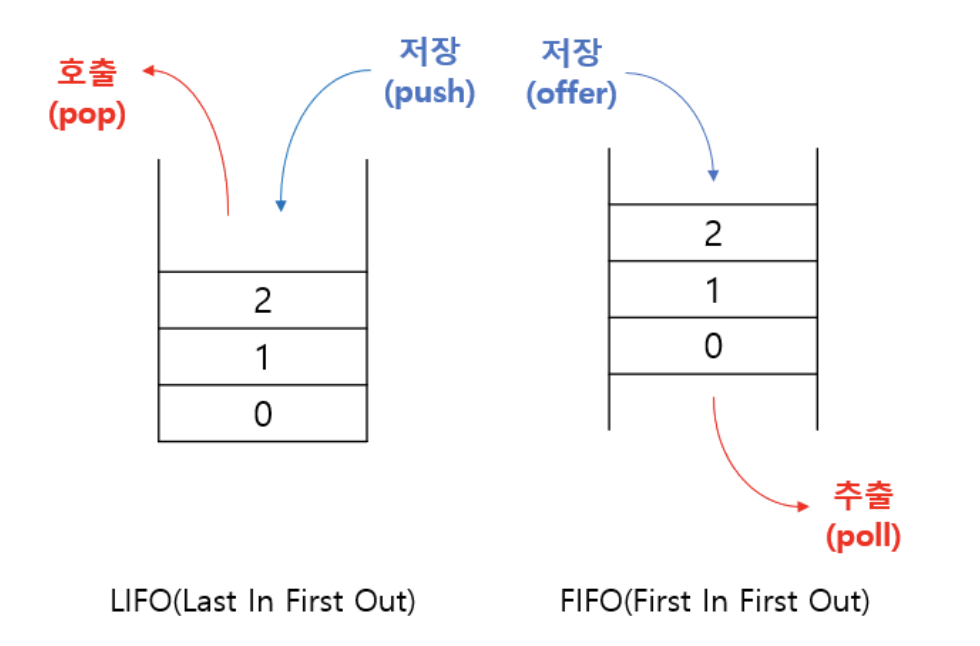
Stack / Queue
Stack : Last In First Out 구조로 마지막에 저장된 데이터를 가장 먼저 꺼내는 구조이다. 순차적으로 데이터를 추가하고 삭제하기 때문에 배열 기반인 ArrayList 같은 컬렉션 클래스가 적합하다.
Queue : First In First Out 구조로 먼저 들어간 데이터를 먼저 꺼내는 구조다. 데이터를 꺼낼때 항상 첫 번째 데이터를 삭제하기 때문에 배열 기반보다 데이터의 추가 삭제가 쉬운 LinkedList가 적합하다.
Deque : Queue의 변형으로 양쪽 끝에서 추가, 삭제가 가능하다.
Singleton
인스턴스를 불필요하게 생성하지 않고, 오직 JVM 내에 한 개의 인스턴스만 생성하여 재사용을 위해 사용되는 디자인 패턴이다. 한 번의 객체 생성으로 재사용이 가능하기 때문에 메모리 낭비를 방지할 수 있다. 또 한 번 생성으로 전역성을 띄기 때문에 다른 객체와 공유가 용이하다.
하지만 싱글톤에게 많은 일을 하게 하거나 많은 데이터를 공유시키면 다른 클래스의 인스턴스간 결합도가 높아지면서 개방-폐쇄 원칙을 위배하는 문제가 발생한다.
하지만 멀티스레드 환경에서 동기화 처리를 해주지 않는 경우 인스턴스가 두 개 생성되는 등 문제가 생길 가능성이 있기 때문에 Thread-safe(멀티스레드 환경에서 동작해도 원래 의도한 형태로 동작하는 코드)가 보장되어야 한다. 또 수정이 어려워지고 테스트하기 어렵다는 단점이 존재한다.
synchronized 키워드 사용을 통해 문제 해결 -> 찾아보기..
’==’ / equals()
== 연산자는 int, boolean 같은 기본 자료형 타입에 대해서는 값을 비교하고, 객체 등 참조타입에 대해서는 주소값을 비교한다. equals() 메서드는 비교하고자 하는 두개의 대상의 값 자체를 비교한다.
hashcode
hashcode는 일반적으로 각 객체의 주소값을 변환하여 생성한 객체의 고유한 정수값이다. 따라서 두 객체가 동일 객체인지 비교할 때 사용할 수 있다.
String의 경우 hashcode()가 재정의 되어 있는데 서로 다른 String 객체도 문자열이 같으면 hashcode()가 같다.
*equals()는 두 객체의 내용이 같은지 확인 / hashcode()는 두 객체가 같은 객체인지 확인
변수 표기법
- 파스칼 표기법 - 자바에서 클래스 명명 규칙으로 첫 클자를 대문자로 하고 + 카멜 표기법이 합쳐진 형태
- 언더스코프 표기법(스네이크) - 단어 사이에 밑줄을 표기하는 형태
- 카멜 표기법 - 두 단어 이상의 변수명 표현시 두 번째 단어부터 첫 글자를 대문자로 표기법, 변수 명명 규칙에서 첫 글자는 반드시 소문자로 한다는 규칙 + 카멜표기법
- 헝가리언 표기법 - 변수 표기시 앞에 접두어로 자료형을 쉽게 알아볼 수 있도록 표기하는 방식
- 케밥 표기법 - 하이픈 ‘-‘ 을 이용하여 단어를 연결하는 표기법
동기화 / 비동기화
작업을 수행하는 A, B가 있을 때 동기식 처리는 A의 작업이 끝나면 B의 작업이 시작하는 것이고, 비동기식 처리는 A의 작업이 끝나든 말든 상관없이 B의 작업이 시작되는 것이다. 즉 동기는 작업이 순차적으로 진행되는 것이 보장되고, 요청에 따른 결과가 한 자리에서 동시에 일어난다 따라서 결과가 나올때까지 대기한다. 비동기는 요청에 따른 응답을 기다리지 않고 바로 다음 동작이 실행되는 것으로 결과가 나올 때까지 다른 작업을 수행할 수 있어 자원을 효율적으로 사용할 수 있다.
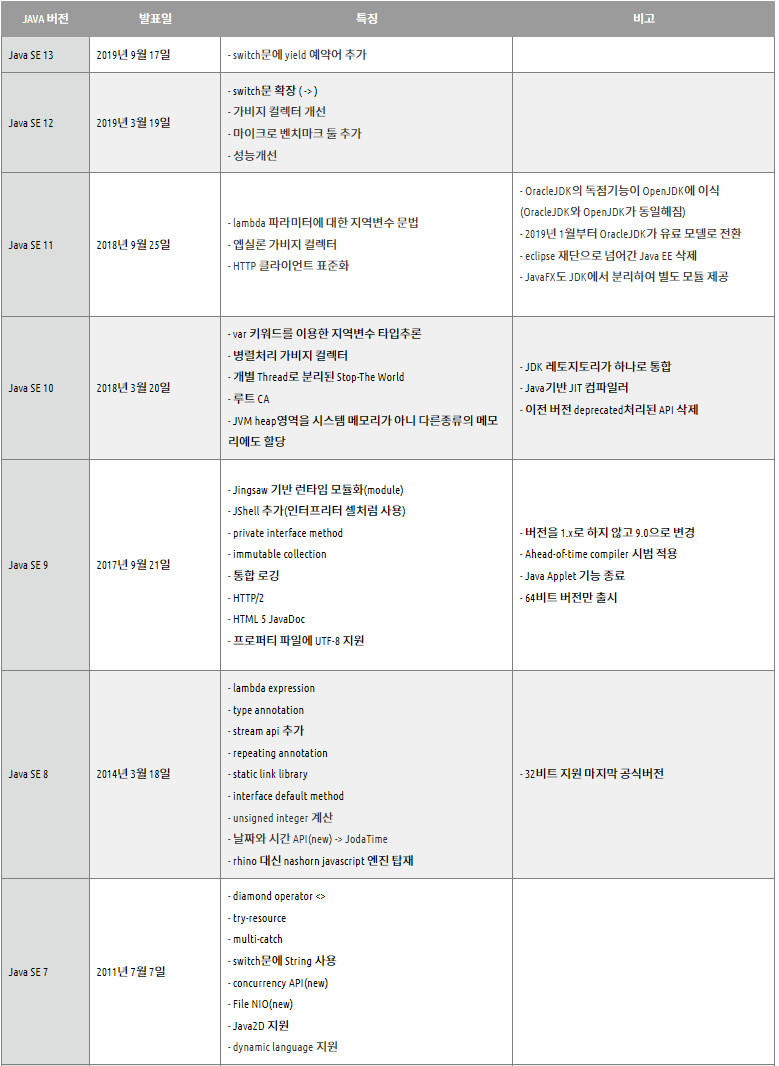
버전별 차이점
큰 특징으로
- java 7 :
- switch 문의 인자로 String 허용
- 제네릭 인스턴스 생성시 type 생략 가능
- java 1.8 :
- 인터페이스 내부에 로직을 포함할 수 있는 default 메서드를 작성할 수 있다.
- 람다표현식
- 새로운 날짜와 시간 API (LocalDate, LocalTime, LocalDateTime)
- java 10 :
- var 키워드를 통한 타입 추론
- 병렬처리 가비지 컬렉션 도입으로 인한 성능 향상